Quality of Experience in Cyber-Physical Social Systems Based on Reinforcement Learning and Game Theory



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Motivation and Related Work
1.2. Paper Contributions and Outline
- For the first time in the literature, visitors are modeled as learning automata via a reinforcement learning mechanism, which allows them to select the most appropriate recommendation for their museum tour. The concept of learning automata is adopted from the control theory where the learning automata entities can make autonomous decisions and selections among available choices by sensing their environment and based on their past decisions. Thus, visitors are able to intelligently sense their environment (e.g., actions of other visitors) while keeping track of their own decisions in order to take more educated and advantageous actions in the future. As time evolves, their decisions converge and visitors select the type of recommendation that will improve their perceived QoE.
- We introduce a holistic approach of QoE-based visiting time management in museums. Each museum visitor aims to maximize his/her perceived QoE in a distributed manner for the selected recommendation. Based on the non-cooperative and distributed nature of managing visiting time, we formulate a maximization problem for each visitor’s QoE function and confront it as a non-cooperative game. To deal with this problem while considering the different types of visitor personas, we follow an approach based on the quasi-concavity of the visitor QoE function in order to conclude at a unique Nash equilibrium point.
- The perceived satisfaction of museum visitors is reflected and represented in a formal and quantitative way by using appropriately defined QoE functions. They are based on the following attributes: (a) time spent on a museum visit, (b) selected type of recommendation, and (c) fulfillment of visitor QoE prerequisites. The key novelty in this work is that the QoE function consists of the following two parts: (a) the pure QoE function and (b) the congestion control function. The pure QoE function reflects the tradeoff of achievable QoE over the time spent on the visit. The congestion control function is sophisticatedly selected in order to achieve fairness among museum visitors with respect to accessing and spending time in the museum.
- The proposed framework enables autonomic visitor-centric management and QoE optimization in a personalized manner, which allows self-* properties, e.g., self-optimization, self-adaptation, etc.
- A two-stage distributed algorithm is proposed to determine the optimal visiting time and recommendation selection for each museum visitor. The output of the visiting time management problem feeds the learning system in a recursive manner in order to build knowledge.
- Detailed numerical results are provided that demonstrate the performance and operational effectiveness and efficiency of the proposed algorithm along with its flexibility and adaptability under various scenarios. The proposed framework was tested with data provided by users via a questionnaire and additional simulation results were then generated to achieve a more thorough analysis. Lastly, the performance of the proposed framework is evaluated against the related state-of-the-art framework and its superiority in terms of achieved QoE is demonstrated.
2. An Overview of the Joint Recommendation Selection & Visiting Time Management Framework
3. Models and Preliminaries
3.1. System Model
3.2. Recommendation Models and Policies
- Recommendation A (): The museum provides a map of the museum at its entrance without visitors waiting in long queues for this service. However, visitors may have to spend a lot of time in order to navigate themselves without guidance in the museum. Moreover, visitors perceived QoE, i.e., , is limited because the information received about exhibits is based only on the corresponding text-tags attached to each exhibit, which provides relevant information about it.
- Recommendation B (): A facilitator is provided by the museum to navigate the visitors in the museum and provide additional useful information about exhibits. Visitors create groups when they arrive at the museum and a facilitator starts the museum tour with the group at specific timeslots. Therefore, museum visitors on average should wait a longer time than in the previous case in order for the group to be created and the touring to start. However, their perceived QoE, i.e., is increased when compared to QA because they gain more information about exhibits and their visit is shorter and more efficient due to its structured and guided nature.
- Recommendation C (): Besides the previously described characteristics of the recommendation , the facilitator offers headphones to the museum visitors so that the information is provided in their native languages. Such groups are typically scheduled to start tours in sparse timeslots and, thus, their waiting time increases. However, the perceived QoE of a visitor, i.e., , increases due to the enhanced obtained service.
3.3. Quality of Experience Function and Modeling
3.4. Penetration Model of Recommendation in Visitors’ Pool
4. Joint Recommendation Selection and Visiting Time Management Problem
4.1. Framework Design
4.2. Recommendation Selection Based on Reinforcement Learning
4.3. Visiting Time Management
- Positivity: , thus ;
- Monotonicity: if then via Equation (10) we conclude that ;
- Scalability: for all , then via Equation (10) we conclude that .
5. RSVTM Algorithm
6. Performance Evaluation and Results
6.1. A Human-In-The-Loop Experiment
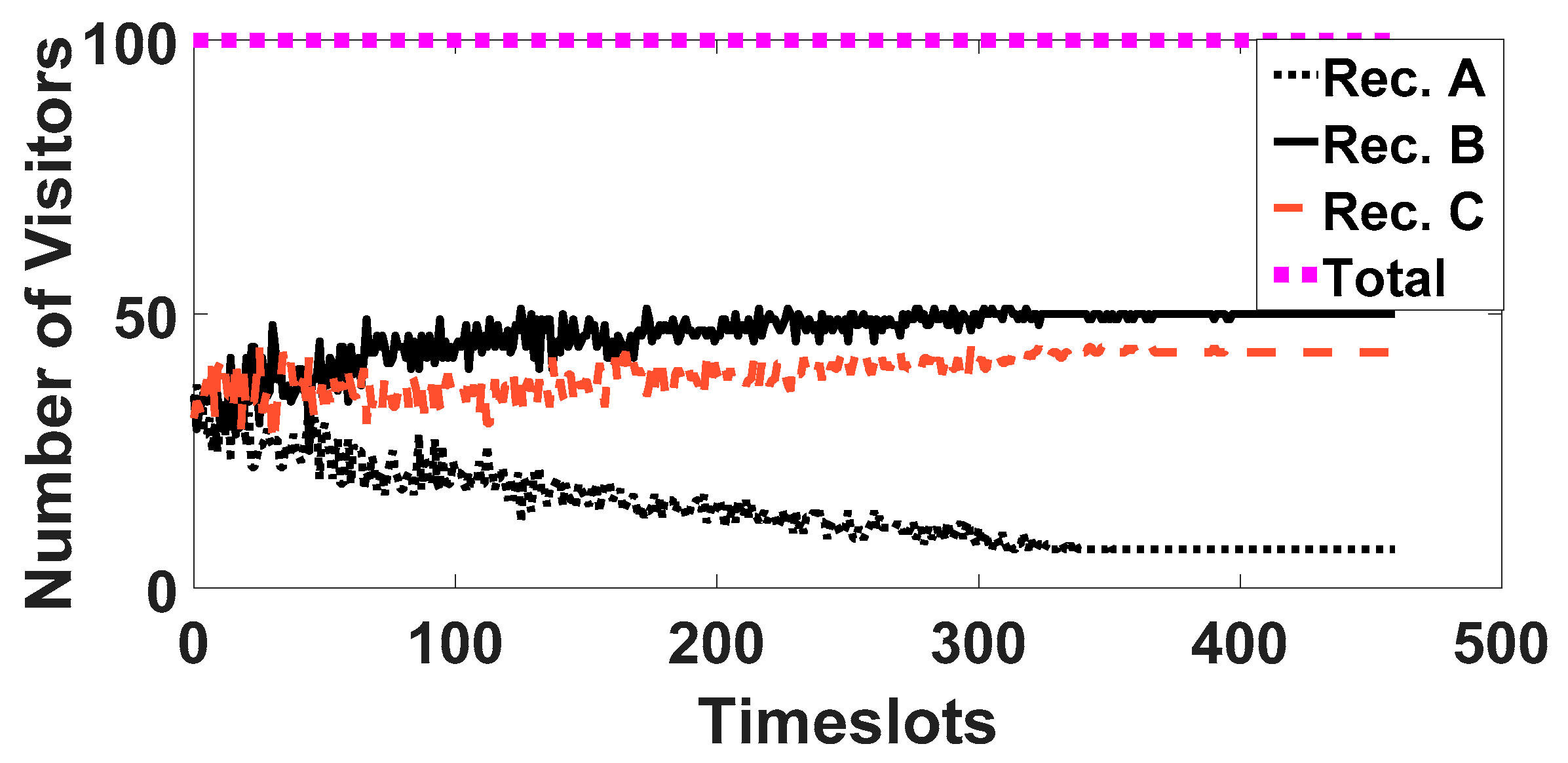
6.2. RSVTM Properties and Operation
6.3. Comparative Study
- (a)
- RSVTM framework: each visitor acts as a stochastic learning automaton that learns through past actions and makes the most beneficial recommendation selection via the RSVTM algorithm,
- (b)
- Random Scenario: each visitor randomly selects a recommendation,
- (c)
- Fixed A (all visitors select Recommendation A),
- (d)
- Fixed B (all visitors select Recommendation B),
- (e)
- Fixed C (all visitors select Recommendation C).
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Veron, E.; Levasseur, M. Ethnographie de l’Exposition; Centre Georges Pompidou, Bibliothèque Publique d’Information: Paris, France, 1989. [Google Scholar]
- Zancanaro, M.; Kuflik, T.; Boger, Z.; Goren-Bar, D.; Goldwasser, D. Analyzing Museum Visitors’ Behavior Patterns. In User Modeling 2007; Conati, C., McCoy, K., Paliouras, G., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4511, pp. 238–246. [Google Scholar]
- De Rojas, C.; Camarero, C. Visitors’ experience, mood and satisfaction in a heritage context: Evidence from an interpretation center. Tour. Manag. 2008, 29, 525–537. [Google Scholar] [CrossRef]
- Sheng, C.W.; Chen, M.C. A study of experience expectations of museum visitors. Tour. Manag. 2012, 33, 53–60. [Google Scholar] [CrossRef]
- Roussou, M.; Katifori, A. Flow, staging, wayfinding, personalization: Evaluating user experience with mobile museum narratives. Multimodal Technol. Interact. 2018, 2, 32. [Google Scholar] [CrossRef]
- Zeng, B. Cultural Centre, Destination Cultural Offer and Visitor Satisfaction. Sustainability 2017, 9, 1984. [Google Scholar] [CrossRef]
- Chittaro, L.; Ieronutti, L. A visual tool for tracing users’ behavior in Virtual Environments. In Proceedings of the Working Conference on Advanced Visual Interfaces, Gallipoli, Italy, 25–28 May 2004; pp. 40–47. [Google Scholar]
- Wright, P. The quality of visitors’ experiences in art museums. New Museol. 1989, 119–148. [Google Scholar]
- Vincent, F.Y.; Lin, S.W.; Chou, S.Y. The museum visitor routing problem. Appl. Math. Comput. 2010, 216, 719–729. [Google Scholar] [CrossRef]
- Chou, S.Y.; Lin, S.W. Museum visitor routing problem with the balancing of concurrent visitors. In Complex Systems Concurrent Engineering; Springer: London, UK, 2007; pp. 345–353. [Google Scholar]
- Mathias, M.; Zhou, F.; Torres-Moreno, J.M.; Josselin, D.; Poli, M.S.; Carneiro Linhares, A. Personalized sightseeing tours: A model for visits in art museums. Int. J. Geogr. Inf. Sci. 2017, 31, 591–616. [Google Scholar] [CrossRef]
- Martinez-Garcia, E.; Raya-Vilchez, J.; Galí, N. Factors Affecting Time Spent Visiting Heritage City Areas. Sustainability 2018, 10, 1824. [Google Scholar] [CrossRef]
- Le Berre, D.; Marquis, P.; Roussel, S. Planning Personalised Museum Visits. In Proceedings of the Twenty-Third International Conference on Automated Planning and Scheduling (ICAPS’13), Rome, Italy, 10–14 June 2013; pp. 1–9. [Google Scholar]
- Mathias, M.; Moussa, A.; Zhou, F.; Torres-Moreno, J.M.; Poli, M.S.; Josselin, D.; Rigat, F. Optimisation using natural language processing: Personalized tour recommendation for museums. In Proceedings of the 2014 Federated Conference on Computer Science and Information Systems (FedCSIS), Warsaw, Poland, 7–10 September 2014; pp. 439–446. [Google Scholar]
- Lykourentzou, I.; Claude, X.; Naudet, Y.; Tobias, E.; Antoniou, A.; Lepouras, G.; Vassilakis, C. Improving museum visitors’ Quality of Experience through intelligent recommendations: A visiting style-based approach. In Proceedings of the 9th International Conference on Intelligent Environments, Athens, Greece, 16–17 July 2015; pp. 507–518. [Google Scholar]
- Tsiropoulou, E.E.; Thanou, A.; Papavassiliou, S. Modelling museum visitors’ Quality of Experience. In Proceedings of the 11th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Thessaloniki, Greece, 20–21 October 2016; pp. 77–82. [Google Scholar]
- Tsiropoulou, E.E.; Thanou, A.; Papavassiliou, S. Quality of Experience-based museum touring: A human in the loop approach. In Social Network Analysis and Mining; Springer: New York, NY, USA, 2017. [Google Scholar]
- Tsiropoulou, E.E.; Thanou, A.; Papavassiliou, S. Self-organizing museum visitor communities: A participatory action research based approach. In Proceedings of the 12th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Bratislava, Slovakia, 9–10 July 2017; pp. 101–105. [Google Scholar]
- Osche, P.E.; Castagnos, S.; Napoli, A.; Naudet, Y. Walk the line: Toward an efficient user model for recommendations in museums. In Proceedings of the 11th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Thessaloniki, Greece, 20–21 October 2016; pp. 83–88. [Google Scholar]
- Chen, M.; Challita, U.; Saad, W.; Yin CDebbah, M. Machine learning for wireless networks with artificial intelligence: A tutorial on neural networks. arXiv, 2017; arXiv:1710.02913. [Google Scholar]
- Apostolopoulos, P.A.; Tsiropoulou, E.E.; Papavassiliou, S. Demand Response Management in Smart Grid Networks: A Two-Stage Game-Theoretic Learning-Based Approach. Mob. Netw. Appl. 2018, 1–14. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, J.; Wu, Q. Distributed learning of equilibria with incomplete, dynamic, and uncertain information in wireless communication networks. In Game Theory Framework Applied to Wireless Communication Networks; IGI Global: Hershey, PA, USA, 2016; pp. 63–86. [Google Scholar]
- Apostol, T.M. Calculus. One-Variable Calculus with an Introduction to Linear Algebra; John Wiley and Sons Ltd.: Hoboken, NJ, USA, 1966; Volume 1. [Google Scholar]
- Questionnaire 2018. Available online: https://goo.gl/forms/zf4WDFADPuZ9iF1x2 (accessed on 6 November 2018).
- Sanjab, A.; Saad, W.; Başar, T. Prospect theory for enhanced cyber-physical security of drone delivery systems: A network interdiction game. arXiv, 2017; arXiv:1702.04240. [Google Scholar]
- Mozaffari, M.; Saad, W.; Bennis MDebbah, M. Unmanned aerial vehicle with underlaid device-to-device communications: Performance and tradeoffs. IEEE Trans. Wirel. Commun. 2016, 15, 3949–3963. [Google Scholar] [CrossRef]









© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsiropoulou, E.E.; Kousis, G.; Thanou, A.; Lykourentzou, I.; Papavassiliou, S. Quality of Experience in Cyber-Physical Social Systems Based on Reinforcement Learning and Game Theory. Future Internet 2018, 10, 108. https://doi.org/10.3390/fi10110108
Tsiropoulou EE, Kousis G, Thanou A, Lykourentzou I, Papavassiliou S. Quality of Experience in Cyber-Physical Social Systems Based on Reinforcement Learning and Game Theory. Future Internet. 2018; 10(11):108. https://doi.org/10.3390/fi10110108
Chicago/Turabian StyleTsiropoulou, Eirini Eleni, George Kousis, Athina Thanou, Ioanna Lykourentzou, and Symeon Papavassiliou. 2018. "Quality of Experience in Cyber-Physical Social Systems Based on Reinforcement Learning and Game Theory" Future Internet 10, no. 11: 108. https://doi.org/10.3390/fi10110108