Multivariate Student versus Multivariate Gaussian Regression Models with Application to Finance

Abstract
:1. Introduction
2. Multivariate Regression Models
2.1. Literature Review
2.2. Univariate Regression Case Reminder
2.3. The Multivariate Regression Model
2.4. Multivariate Normal Error Vector
2.5. Uncorrelated Multivariate Student (UT) Error Vector
2.6. Independent Multivariate Student Error Vector
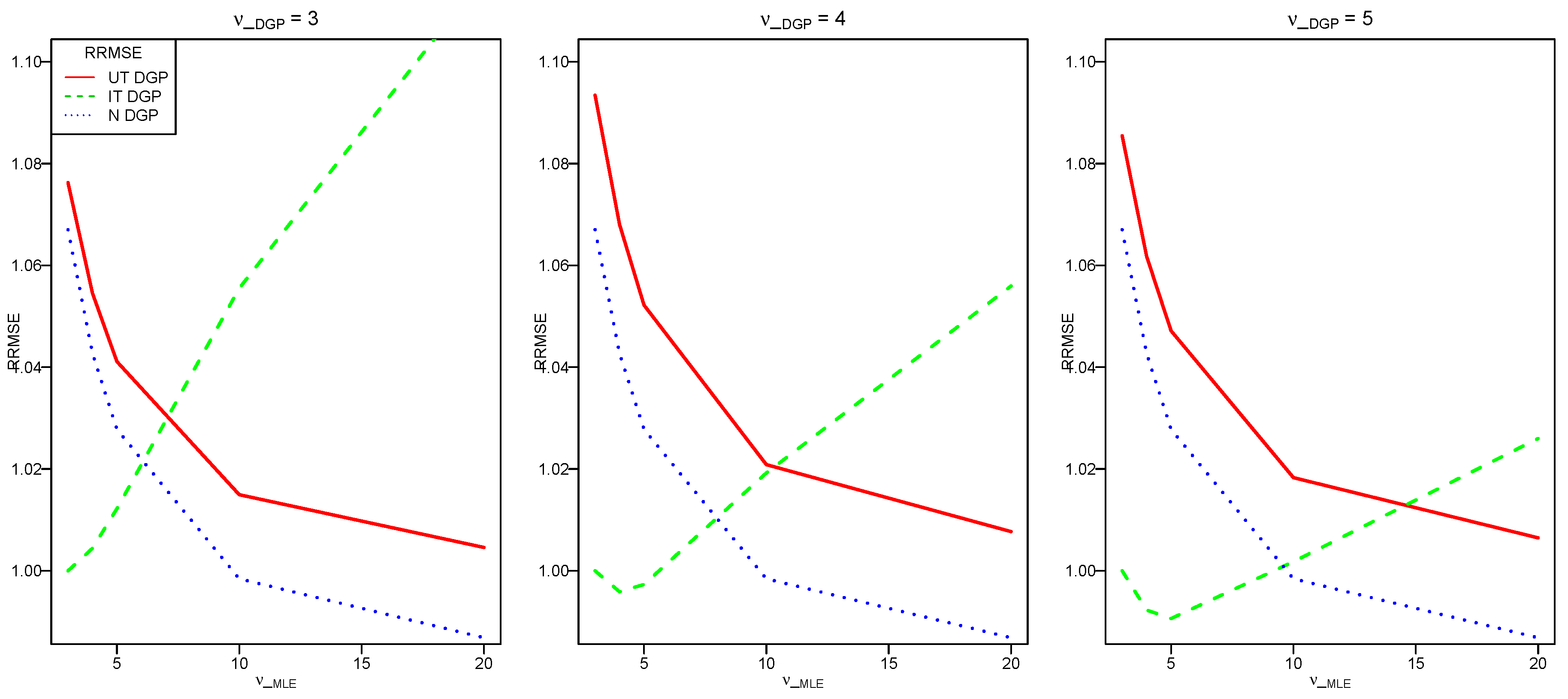
3. Simulation Study
3.1. Design
3.2. Estimators of the Parameters
3.3. Estimators of the Variance Parameters
4. Selection between the Gaussian and IT Models
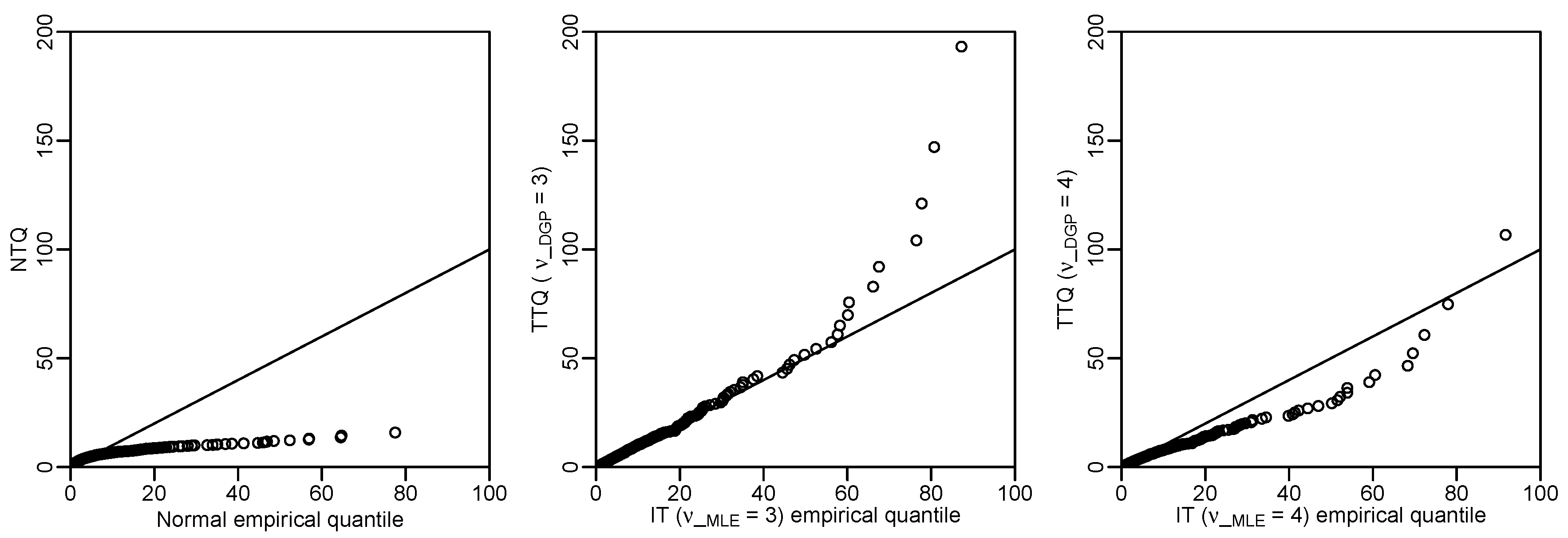
4.1. Distributions of Mahalanobis Distances
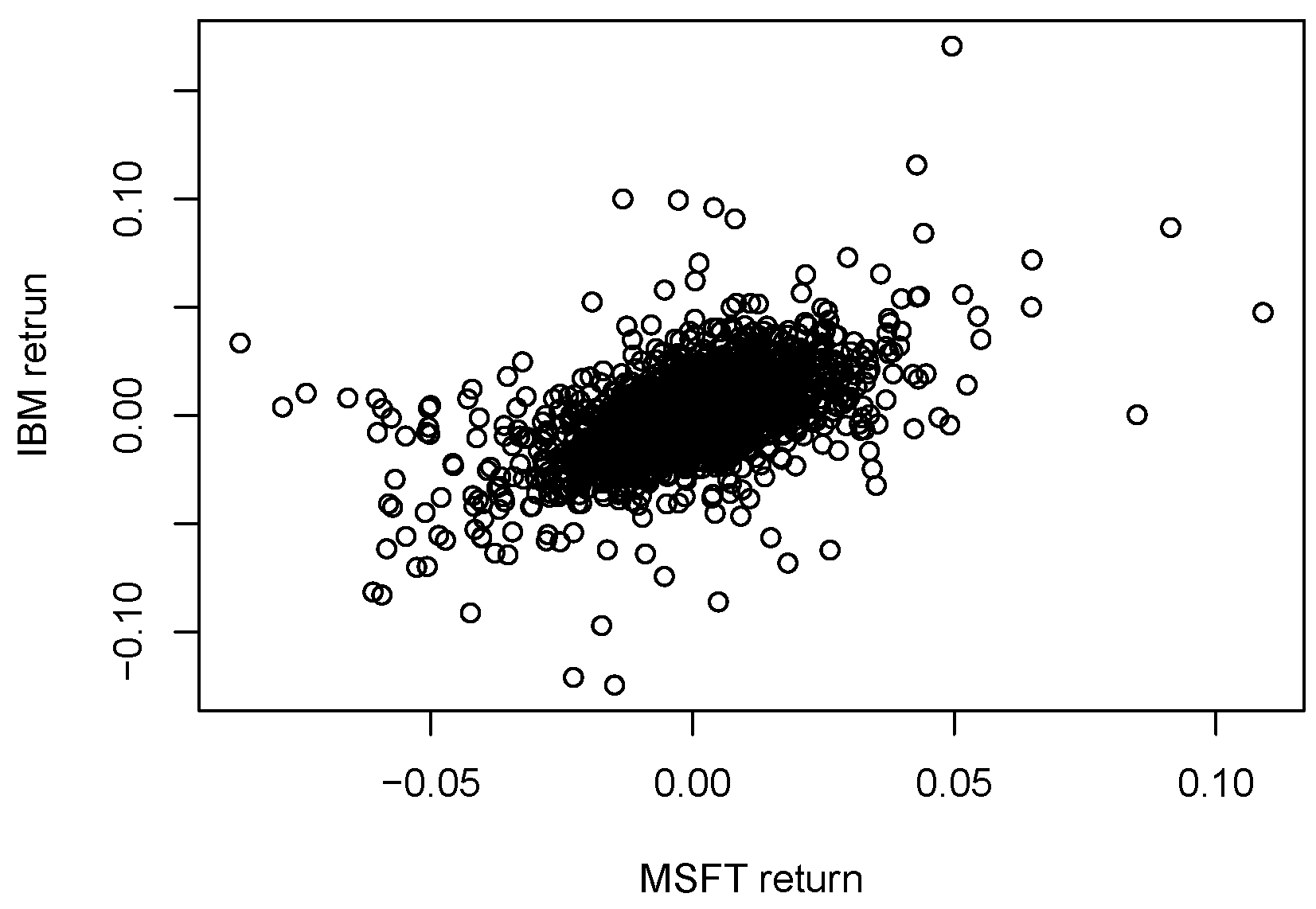
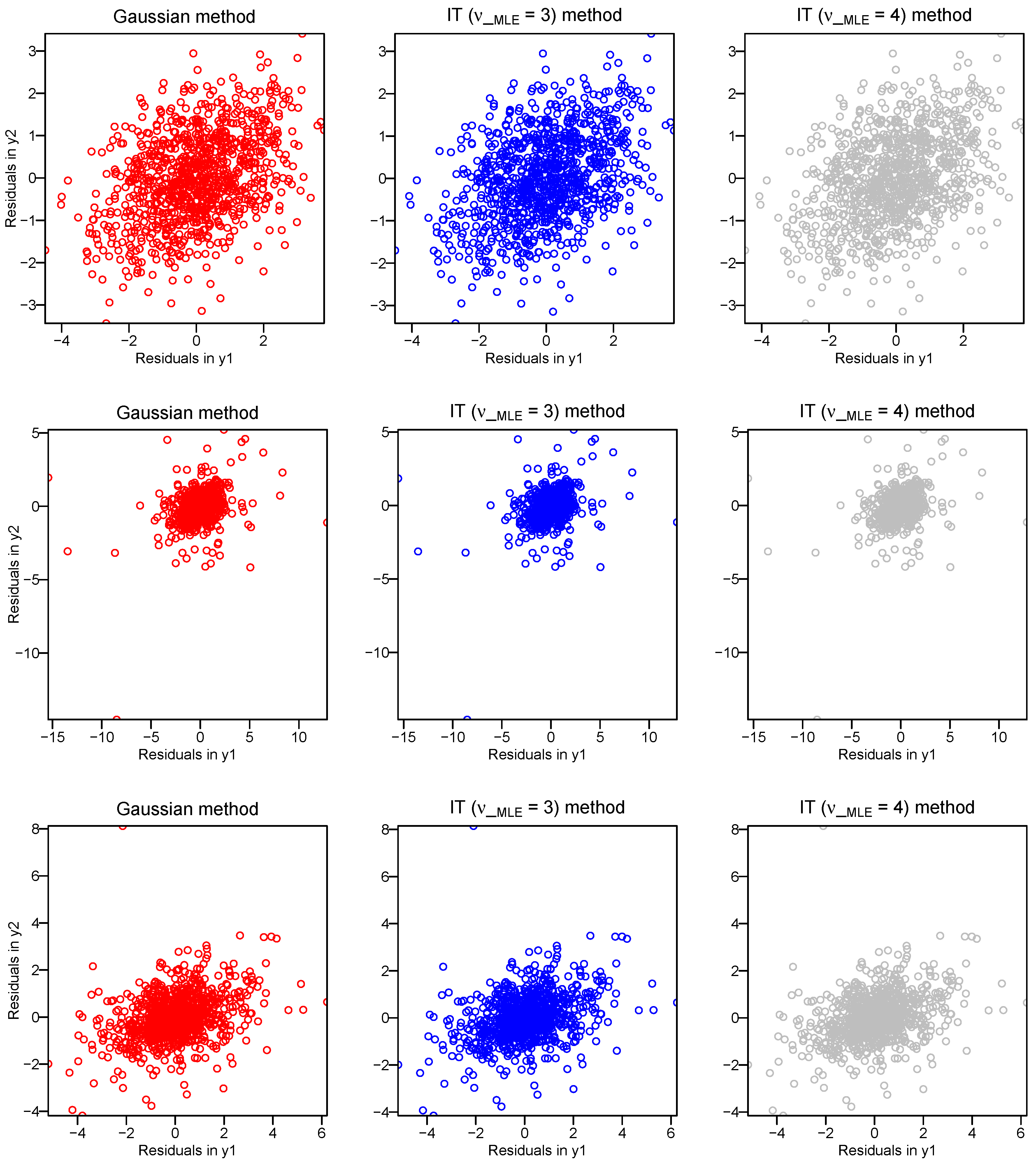
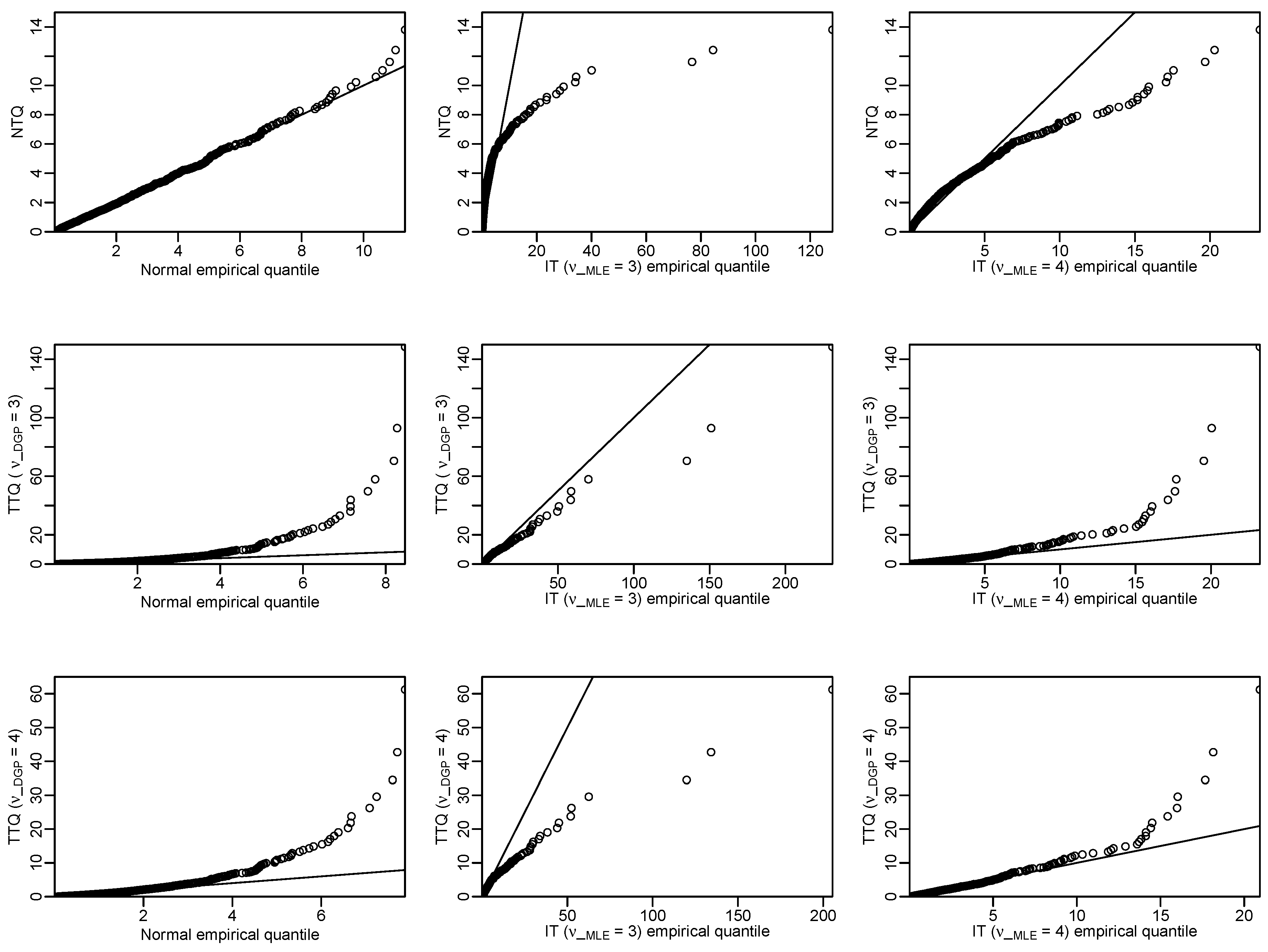
4.2. Examples
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| EM | Expectation-maximization |
| MLE | Maximum likelihood estimator |
| N | Normal (Gaussian) model |
| IT | Independent multivariate Student |
| UT | Uncorrelated multivariate Student |
| RB | Relative bias |
| MSE | Mean squared error |
| RRMSE | Root relative mean squared error |
| DGP | Data-generating process |
Appendix A
References
- Bilodeau, Martin, and David Brenner. 1999. Theory of Multivariate Statistics (Springer Texts in Statistics). Berlin: Springer, ISBN 978-0-387-22616-3. [Google Scholar]
- Croux, Christophe, Mohammed Fekri, and Anne Ruiz-Gazen. 2010. Fast and robust estimation of the multivariate errors in variables model. Test 19: 286–303. [Google Scholar] [CrossRef]
- Dempster, Arthur P., Nan M. Laird, and Donald B. Rubin. 1978. Iteratively Reweighted Least Squared for Linear Regression when Errors are Normal/Independent distributed. Multivariate Analysis V 5: 35–37. [Google Scholar]
- Dogru, Fatma Zehra, Y. Murat Bulut, and Olcay Arslan. 2018. Double Reweighted Estimators for the Parameters of the Multivariate t distribution. Communications in Statistics-Theory and Methods 47: 4751–71. [Google Scholar] [CrossRef]
- Fernandez, Carmen, and Mark F. J. Steel. 1999. Multivariate Student t- Regression Models: Pitfalls and Inference. Biometrika Trust 86: 153–67. [Google Scholar] [CrossRef]
- Fung, Thomas, and Eugene Seneta. 2010. Modeling and Estimating for Bivariate Financial Returns. International Statistical Review 78: 117–33. [Google Scholar] [CrossRef]
- Fraser, Donald Alexander Stuart. 1979. Inference and Linear Models. New York: McGraw Hill, ISBN 9780070219106. [Google Scholar]
- Fraser, Donald Alexander Stuart, and Kai Wang Ng. 1980. Multivariate regression analysis with spherical error. Multivariate Analysis 5: 369–86. [Google Scholar]
- Gnanadesikan, Ram, and Jon R. Kettenring. 1972. Robust estimates, residuals, and outlier detection with multiresponse data. Biometrics 28: 81–124. [Google Scholar] [CrossRef]
- Hofert, Marius. 2003. On Sampling from the Multivariate t Distribution. The R Journal 5: 129–36. [Google Scholar] [CrossRef]
- Hu, Wenbo, and Alec N. Kercheval. 2009. Portfolio optimization for Student t and skewed t returns. Quantitative Finance 10: 129–36. [Google Scholar] [CrossRef]
- Huber, Peter J., and Elvezio M. Ronchetti. 2009. Robust Statistics. Hoboken: Wiley, ISBN 9780470129906. [Google Scholar]
- Johnson, Norman L., and Samuel Kotz. 1972. Student multivariate distribution. In Distribution in Statistics: Continuous Multivariate Distributions. Michigan: Wiley Publishing House, ISBN 9780471443704. [Google Scholar]
- Kan, Raymond, and Guofu Zhou. 2017. Modeling non-normality using multivariate t: implications for asset pricing. China Finance Review International 7: 2–32. [Google Scholar] [CrossRef]
- Katz, Jonathan N., and Gary King. 1999. A Statistical Model for Multiparty Electoral Data. American Political Science Review 93: 15–32. [Google Scholar] [CrossRef]
- Kelejian, Harry H., and Ingmar R. Prucha. 1985. Independent or Uncorrelated Disturbances in Linear Regression. Economics Letters 19: 35–38. [Google Scholar] [CrossRef]
- Kent, John T., David E. Tyler, and Yahuda Vard. 1994. A curious likelihood identity for the multivariate t-distribution. Communications in Statistics-Simulation and Computation 23: 441–53. [Google Scholar] [CrossRef]
- Kotz, Samuel, and Saralees Nadarajah. 2004. Multivariate t Distributions and Their Applications. Cambridge: Cambridge University Press, ISBN 9780511550683. [Google Scholar]
- Lange, Kenneth, Roderick J. A. Little, and Jeremy Taylor. 1989. Robust Statistical Modeling Using the t-Distribution. International Statistical Review 84: 881–96. [Google Scholar] [CrossRef]
- Lange, Kenneth, and Janet S. Sinsheimer. 1993. Normal/Independent Distributions and Their Applications in Robust Regression. Journal of Computational and Graphical Statistics 2: 175–98. [Google Scholar] [CrossRef]
- Liu, Chuanhai, and Donald B. Rubin. 1995. ML estimation of the t distribution using EM and its extensions, ECM and ECME. Statistica Sinica 5: 19–39. [Google Scholar]
- Liu, Chuanhai. 1997. ML Estimation of the Multivariate t Distribution and the EM Algorithm. J. Multivar. Anal. 63: 296–312. [Google Scholar] [CrossRef]
- Maronna, Ricardo Antonio. 1976. Robust M-Estimators of Multivariate Location and Scatter. The Annals of Statistics 4: 51–67. [Google Scholar] [CrossRef]
- McNeil, Alexander J., Rüdiger Frey, and Paul Embrechts. 2005. Quantitative Risk Management: Concepts, Techniques and Tools. Vol. 3, Princeton: Princeton University Press. [Google Scholar]
- Platen, Eckhard, and Renata Rendek. 2008. Empirical Evidence on Student-t Log-Returns of Diversified World Stock Indices. Journal of Statistical Theory and Practice 2: 233–51. [Google Scholar] [CrossRef]
- Prucha, Ingmar R., and Harry H. Kelejian. 1984. The Structure of Simultaneous Equation Estimators: A generalization Towards Nonnormal Disturbances. Econometrica 52: 721–36. [Google Scholar] [CrossRef]
- Roth, Michael. 2013. On the Multivariate t Distribution. Report Number: LiTH-ISY-R-3059. Linkoping: Department of Electrical Engineering, Linkoping University. [Google Scholar]
- Seber, George Arthur Frederick. 2008. Multivariate Observations. Hoboken: John Wiley & Sons, ISBN 9780471881049. [Google Scholar]
- Singh, Radhey. 1988. Estimation of Error Variance in Linear Regression Models with Errors having Multivariate Student t-Distribution with Unknown Degrees of Freedom. Economics Letters 27: 47–53. [Google Scholar] [CrossRef]
- Small, N. J. H. 1978. Plotting squared radii. Biometrics 65: 657–58. [Google Scholar] [CrossRef]
- Sutradhar, Brajendra C., and Mir M. Ali. 1986. Estimation of the Parameters of a Regression Model with a Multivariate t Error Variable. Communication Statistics Theory and Method 15: 429–50. [Google Scholar] [CrossRef]
- Zellner, Arnold. 1976. Bayesian and Non-Bayesian Analysis of the Regression Model with Multivariate Student-t Error Terms. Journal of the American Statistical Association 71: 400–5. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Distribution |
|---|---|
| N | |
| UT | |
| IT |
| DGP | N | UT () | IT () | ||||
|---|---|---|---|---|---|---|---|
| Methods | Estimators | RB (%) | RRMSE | RB (%) | RRMSE | RB (%) | RRMSE |
| −0.07 | 1.00 | −0.06 | 1.00 | −0.09 | 1.48 | ||
| 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.48 | ||
| −0.02 | 1.00 | −0.01 | 1.00 | −0.07 | 1.46 | ||
| −0.00 | 1.00 | −0.00 | 1.00 | −0.00 | 1.46 | ||
| −0.09 | 1.04 | −0.09 | 1.09 | −0.03 | 1.00 | ||
| 0.00 | 1.04 | 0.00 | 1.09 | 0.00 | 1.00 | ||
| −0.04 | 1.07 | −0.02 | 1.08 | −0.03 | 1.00 | ||
| −0.00 | 1.07 | −0.00 | 1.08 | −0.00 | 1.00 | ||
| DGP | N | UT () | IT () | |||
|---|---|---|---|---|---|---|
| Estimators | Bias | MSE | Bias | MSE | Bias | MSE |
| Methods | DGP | N | UT | IT | ||||
|---|---|---|---|---|---|---|---|---|
| RRMSE | ||||||||
| N | 1.00 | 1.00 | 1.00 | 1.00 | 1.48 | 1.22 | 1.14 | |
| 1.00 | 1.00 | 1.00 | 1.00 | 1.48 | 1.23 | 1.14 | ||
| 1.00 | 1.00 | 1.00 | 1.00 | 1.46 | 1.22 | 1.13 | ||
| 1.00 | 1.00 | 1.00 | 1.00 | 1.46 | 1.22 | 1.13 | ||
| IT () | 1.04 | 1.09 | 1.09 | 1.08 | 1.00 | 1.00 | 1.01 | |
| 1.04 | 1.09 | 1.09 | 1.08 | 1.00 | 1.00 | 1.01 | ||
| 1.07 | 1.08 | 1.10 | 1.08 | 1.00 | 1.00 | 1.01 | ||
| 1.07 | 1.08 | 1.09 | 1.09 | 1.00 | 1.00 | 1.01 | ||
| IT () | 1.02 | 1.07 | 1.06 | 1.06 | 1.00 | 1.00 | 1.00 | |
| 1.01 | 1.06 | 1.06 | 1.05 | 1.00 | 1.00 | 1.00 | ||
| 1.04 | 1.06 | 1.07 | 1.06 | 1.00 | 1.00 | 1.00 | ||
| 1.04 | 1.05 | 1.07 | 1.06 | 1.00 | 1.00 | 1.00 | ||
| IT () | 1.00 | 1.05 | 1.05 | 1.04 | 1.01 | 1.00 | 1.00 | |
| 1.00 | 1.05 | 1.05 | 1.04 | 1.01 | 1.00 | 1.00 | ||
| 1.03 | 1.04 | 1.05 | 1.05 | 1.01 | 1.00 | 1.00 | ||
| 1.03 | 1.04 | 1.05 | 1.05 | 1.01 | 1.00 | 1.00 | ||
| Methods | DGP | N | UT () | IT () | |||
|---|---|---|---|---|---|---|---|
| Bias | MSE | Bias | MSE | Bias | MSE | ||
| N | |||||||
| 58 | |||||||
| IT | |||||||
| Methods | DGP | N | UT | IT | ||||
|---|---|---|---|---|---|---|---|---|
| RB (%) | ||||||||
| N | −0.14 | −0.06 | −0.06 | −0.06 | −1.13 | −0.24 | 0.02 | |
| −0.21 | −5.23 | −3.34 | −2.31 | 0.35 | −0.08 | −0.12 | ||
| −0.18 | −5.17 | −3.33 | −2.20 | −1.77 | −0.30 | −0.09 | ||
| IT, | −0.05 | −0.06 | −0.06 | −0.06 | −0.06 | −0.04 | −0.02 | |
| 99.99 | 90.25 | 93.89 | 95.80 | −0.72 | 32.79 | 50.12 | ||
| 100.05 | 90.60 | 93.90 | 96.03 | −0.73 | 32.79 | 50.13 | ||
| IT, | −0.05 | −0.06 | −0.06 | −0.06 | −0.06 | −0.04 | −0.01 | |
| 42.62 | 35.80 | 38.32 | 39.68 | −24.66 | −0.24 | 11.18 | ||
| 42.66 | 36.01 | 38.34 | 39.85 | −24.67 | −0.23 | 11.19 | ||
| IT, | −0.06 | −0.06 | −0.06 | −0.06 | −0.06 | −0.04 | −0.00 | |
| 24.71 | 18.85 | 21.03 | 22.23 | −31.75 | −10.13 | −0.14 | ||
| 24.74 | 19.02 | 21.04 | 22.38 | 1.76 | −10.13 | −0.14 | ||
| Methods | DGP | N | UT | IT | ||||
|---|---|---|---|---|---|---|---|---|
| RRMSE | ||||||||
| N | 1.00 | 1.00 | 1.00 | 1.00 | 3.21 | 1.91 | 1.42 | |
| 1.00 | 1.00 | 1.00 | 1.00 | 14.33 | 2.65 | 1.64 | ||
| 1.00 | 1.00 | 1.00 | 1.00 | 8.50 | 2.24 | 1.78 | ||
| IT, | 0.97 | 1.09 | 1.09 | 1.09 | 1.00 | 1.00 | 1.01 | |
| 22.07 | 2.05 | 2.11 | 2.16 | 1.00 | 5.89 | 9.18 | ||
| 22.45 | 2.08 | 2.11 | 2.16 | 1.00 | 5.77 | 9.13 | ||
| IT, | 0.95 | 1.06 | 1.06 | 1.06 | 1.01 | 1.00 | 1.00 | |
| 9.49 | 1.46 | 1.47 | 1.48 | 4.04 | 1.00 | 2.31 | ||
| 9.65 | 1.48 | 1.47 | 1.48 | 4.00 | 1.00 | 2.30 | ||
| IT, | 0.94 | 1.05 | 1.05 | 1.05 | 1.01 | 1.00 | 1.00 | |
| 5.58 | 1.27 | 1.27 | 1.28 | 5.16 | 1.99 | 1.00 | ||
| 5.68 | 1.28 | 1.28 | 1.27 | 5.10 | 1.95 | 1.00 | ||
| Hypothesis | Toy DGP | Financial Data | ||
|---|---|---|---|---|
| Methods | N | IT, | IT, | |
| N | 0.546 | |||
| IT, | 0.405 | 0.033 | 0.882 | |
| IT, | 0.023 | 0.303 | 0.049 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.H.A.; Ruiz-Gazen, A.; Thomas-Agnan, C.; Laurent, T. Multivariate Student versus Multivariate Gaussian Regression Models with Application to Finance. J. Risk Financial Manag. 2019, 12, 28. https://doi.org/10.3390/jrfm12010028
Nguyen THA, Ruiz-Gazen A, Thomas-Agnan C, Laurent T. Multivariate Student versus Multivariate Gaussian Regression Models with Application to Finance. Journal of Risk and Financial Management. 2019; 12(1):28. https://doi.org/10.3390/jrfm12010028
Chicago/Turabian StyleNguyen, Thi Huong An, Anne Ruiz-Gazen, Christine Thomas-Agnan, and Thibault Laurent. 2019. "Multivariate Student versus Multivariate Gaussian Regression Models with Application to Finance" Journal of Risk and Financial Management 12, no. 1: 28. https://doi.org/10.3390/jrfm12010028