Simple Stopping Criteria for Information Theoretic Feature Selection



Computational NeuroEngineering Laboratory, University of Florida, Gainesville, FL 32611, USA
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(1), 99; https://doi.org/10.3390/e21010099
Submission received: 4 December 2018
/
Revised: 21 January 2019
/
Accepted: 21 January 2019
/
Published: 21 January 2019
(This article belongs to the Special Issue Information Theoretic Learning and Kernel Methods)
Abstract
:Feature selection aims to select the smallest feature subset that yields the minimum generalization error. In the rich literature in feature selection, information theory-based approaches seek a subset of features such that the mutual information between the selected features and the class labels is maximized. Despite the simplicity of this objective, there still remain several open problems in optimization. These include, for example, the automatic determination of the optimal subset size (i.e., the number of features) or a stopping criterion if the greedy searching strategy is adopted. In this paper, we suggest two stopping criteria by just monitoring the conditional mutual information (CMI) among groups of variables. Using the recently developed multivariate matrix-based Rényi’s -entropy functional, which can be directly estimated from data samples, we showed that the CMI among groups of variables can be easily computed without any decomposition or approximation, hence making our criteria easy to implement and seamlessly integrated into any existing information theoretic feature selection methods with a greedy search strategy.
1. Introduction
Feature selection aims to find the smallest feature subset that yields the minimum generalization error [1]. As a fundamental problem in machine learning and statistics communities, feature selection is relevant to understand better the classification problem at hand in many applications, such as medical decision making, economics, and engineering [2]. Consequently, it also has a large impact on interpretability or explainability, which is totally missing in most current deep learning techniques [3]. Ever since the pioneering work of Battiti [4], information theoretic feature selection has been extensively investigated in signal processing and machine learning communities (e.g., [5,6,7]). Given a set of F features (each denotes an attribute) and their corresponding class labels y, these methods seek a subset of informative attributes , such that the mutual information (MI) between and y (i.e., ) is maximized [8].
Despite the simplicity of this objective, several open problems still remain in information theoretic feature selection. These include, for example, the reliable estimation of in high-dimensional space, in which denotes an arbitrary subset of S [8,9]. In fact, may contain both continuous and discrete variables, whereas y is a discrete variable. There is no universal agreement on the definition of MI between a discrete variable and a group of mixed variables, let alone its estimation [10]. Therefore, almost all existing information theoretic feature selection methods estimate by first discretizing the feature space and then approximating with low-order MI quantities, such as relevancy , joint relevancy , conditional relevancy , redundancy , conditional redundancy , and synergy [11]. These low-order MI quantities only capture the low-order feature dependency and, hence, severely limit the performance of existing information theoretic feature selection methods [12]. Interested readers can check Reference [8] for a systemic review of 17 popular low-order information theoretic criteria in the last two decades. Apart from MI estimation, another challenging problem, which also impacts performance greatly, is the automatic determination of the optimal size of . This is because most of the information theoretic feature selection methods do not have a stopping criterion [1]. Hence, the user must find criteria to estimate the best number of features.
Regarding the first problem, our recent work [13] suggested that can be efficiently estimated using the normalized eigenspectrum of a Hermitian matrix of the projected data in the reproducing kernel Hilbert space (RKHS). In this paper, we expand on the topic of Reference [13] and illustrate that the novel multivariate matrix-based Rényi’s -entropy functional also enables simple strategies to guide the early stopping in the greedy search procedure of information theoretic feature selection methods.
Before presenting our methods, we first briefly review related work and also point out a common issue in most previous methods. Perhaps the most acknowledged stopping criterion for information theoretic feature selection is that the value of stops increasing or reaches its maximum [14,15]. Given a new feature , this rule suggests that we should stop selection if . An alternative approach is using the concept of the Markov blanket (MB) [16,17]. By definition, the MB M of a target variable y is the smallest subset of S such that y is conditional independent of the rest of the variables , i.e., [1]. From the perspective of information theory, this rule indicates that we should stop selection if the conditional mutual information (CMI) is zero.
Despite their simplicity, both rules are overoptimistic and cannot be applied in practice. In fact, by the chain rule of mutual information [18], we have:
and:
According to Equations (1) and (2), the feature selection is stopped if and only if the CMI item or is zero. Unfortunately, since CMI is always non-negative [18] and rarely reduces to zero in practice due to statistical variation and chance agreement between variables [19], we always have and . That is to say, the maximum value of is exactly and a perfect MB of y is perhaps the feature set S itself.
Admittedly, one can say that we can stop the selection if the increment of or the decrement of approaches zero with a tiny residual. Unfortunately, since we still do not have a reliable estimator of MI and CMI in high-dimensional space (before [13]), it is hard for us to measure or determine how small the residual terms are.
To the best of our knowledge, there are only two methods in the literature that can stop the greedy search. François et al. [14] suggested monitoring the value of using a permutation test [20]. Specifically, suppose the new feature selected in the current iteration is , the authors create a random permutation of (without permuting the corresponding y), denoted . If is not significantly larger than , can be discarded and the feature selection is stopped. Moreover, François et al. also suggested using the k-nearest neighbors (KNN) estimator [21] to estimate . However, their results indicated that this estimator may result in negative CMI quantities no matter the selection of k. Vinh et al. [19], on the other hand, proposed monitoring the increment of after adding (i.e., ) using distribution. If is smaller than a threshold obtained from the distribution at a certain significance level, the feature selection is stopped. However, one should note that the distribution assumption holds if and only if [19,22]. Unfortunately, as we emphasized earlier, the CMI quantity rarely reduces to zero in practice. This is also the reason why Vinh’s method is likely to severely underestimate the require number of features, as is illustrated in the experiments.
Different from previous work, we suggest using the novel multivariate matrix-based Rényi’s -entropy functional [23] to estimate MI and CMI in high-dimensional space. We also present two simple stopping criteria based on these new estimators. To summarize, our main contributions are twofold:
- Efficient stopping criteria for feature selection are still missing in the literature. We present two rules based on the new estimators of information theoretic descriptors of Rényi’s -entropy in RKHS. One should note that the properties, utilities, and possible applications of these new estimators are rather new and mostly unknown to practitioners;
- Our criteria are extremely simple and flexible. First, the proposed tests and stopping criteria can be incorporated into any sequential feature selection procedure, such as mutual information-based feature selection (MIFS) [4] and maximum-relevance minimum-redundancy (MRMR) [24]. Second, benefiting from the higher accuracy of the estimation, we demonstrated that one can simply use a threshold in a heuristic manner, which is very valuable for practitioners across different domains.
2. Simple Stopping Criteria for Information Theoretic Feature Selection
In this section, we start with a brief introduction to the recently proposed matrix-based Rényi’s -entropy functional and its multivariate extension [13]. The novel definition yields two simple stopping criteria as presented below.
2.1. Matrix-Based Rényi’s -Entropy Functional and Its Multivariate Extension
In information theory, a natural extension of the well-known Shannon’s entropy is Rényi’s -order entropy [25]. For a random variable X with probability density function (PDF) in a finite set , the -entropy is defined as:
Based on this entropy definition, Rényi then proposed a divergence measure (-relative entropy) between random variables with PDFs f and g:
Rényi’s entropy and divergence have a long track record of usefulness in information theory and its applications [26]. Unfortunately, the accurate PDF estimation impedes its more widespread adoption in data driven science. To solve this problem, References [13,23] suggest similar quantities that resemble quantum Rényi’s entropy [27] in terms of the normalized eigenspectrum of the Hermitian matrix of the projected data in RKHS, thus estimating the entropy and joint entropy among two or multiple variables directly from data without PDF estimation. For brevity, we directly give the definition.
Definition 1.
Let be a real valued positive definite kernel that is also infinitely divisible [28]. Given and the Gram matrix K obtained from κ on all pairs of exemplars, that is, , a matrix-based analogue to Rényi’s α-entropy for X can be defined, using a normalized positive definite (NPD) matrix A of size and trace 1, by:
where and denotes the i-th eigenvalue of A.
The matrix functional in Equation (5) bears a lot of resemblance to well-known operational quantities from quantum information theory [27], where the density matrix (operator) can be employed to compute expectation over an observable represented by the operator A as . For instance, the quantum extensions of Rényi’s entropy [29,30] is given by:
Although some properties of Equation (6) also apply to Equation (5), the matrix-based estimation is very different, since it deals with the Gram matrix obtained from pairwise evaluations of a positive definite kernel from data samples. Consequently, this novel definition not only involves the functional, but also the kernels employed to construct positive definite matrix.
Definition 2.
Given a collection of n samples , where the superscript i denotes the sample index, each sample contains k () measurements , , ⋯, obtained from the same realization, and the positive definite kernels , , ⋯, , let us denote containing the l-th measurement of all samples, the Rényi’s α-order joint-entropy among k variables (denote here ) can be defined using the following matrix-based analogue:
where , , ⋯, , and ⊙ denotes the Hadamard product.
The following two corollaries (proved in Reference [13]) serve as a foundation for our Definition 2. Specifically, Corollary 1 indicates that the joint entropy of a set of variables is greater than or equal to the maximum of all of the individual entropies of the variables in the set, whereas Corollary 2 suggests that the joint entropy of a set of variable is less than or equal to the sum of the individual entropies of the variables in the set.
Corollary 1.
Let be the index set . We partition into two complementary subsets and . For any , denote all indices in with , where stands for cardinality. Similarly, denote all indices in with . Also let , , ⋯, be C positive definite matrices with trace 1 and non-negative entries, and , for . Then, the following two inequalities hold:
Corollary 2.
Let , , ⋯, be C positive definite matrices with trace 1 and non-negative entries, and , for . Then, the following two inequalities hold:
2.2. Stopping Criteria Based on Conditional Mutual Information
Denote , the selected features in , , the remaining features in , given the entropy and joint entropy estimators shown in Equations (5)–(7), the MI between y and (i.e., ) and the CMI between y and conditioning on (i.e., ), with analogue properties to Shannon’s definition of MI and CMI (by Shannon’s definition, and , where denotes entropy or joint entropy), which can be estimated with Equations (12) and (13), respectively, where , , ⋯, , B, , , ⋯, denote the Gram matrices evaluated over , , ⋯, , y, , , ⋯, , respectively, and ⊙ denotes the Hadamard product.
As can be seen, the multivariate matrix-based Rényi’s -entropy functional enables simple estimation of both MI and CMI in high-dimensional space, no matter the data characteristics (e.g., continuous or discrete) in each dimension. In contrast to previous definitions on Rényi’s -mutual information [31] that stem from a probabilistic perspective using expectations over PDFs, Equations (12) and (13) directly estimate MI and CMI in RKHS. Benefiting from these elegant expressions, suppose the new feature selected in the current iteration is , we present two simple criteria to guide the early stopping of the greedy search. Specifically, we aim to test the “goodness-of-fit” of the MB condition, i.e., is the MB of y given . Intuitively, if approaches zero, the MB condition is approximately satisfied.
Criterion I.
If , where refers to a tiny threshold, then we should stop the selection. We term this criterion CMI-heuristic, since is a heuristic value.
Criterion II.
Motivated by Reference [14], in order to quantify how affects the MB condition, we created a random permutation of (without permuting the corresponding y), denoted . If is not significantly smaller than , can be discarded and the feature selection is stopped. We term this criterion CMI-permutation (see Algorithm 1 for more details, where is an indicator function which is 1 if its argument is true and 0 otherwise.).
| Algorithm 1 CMI-permutation |
| Input: Feature set S; Selected feature subset ; Class labels y; Selected feature in the current iteration ; Permutation number P; Significance level . Output: decision (Stop selection or Continue selection). |
3. Experiments and Discussions
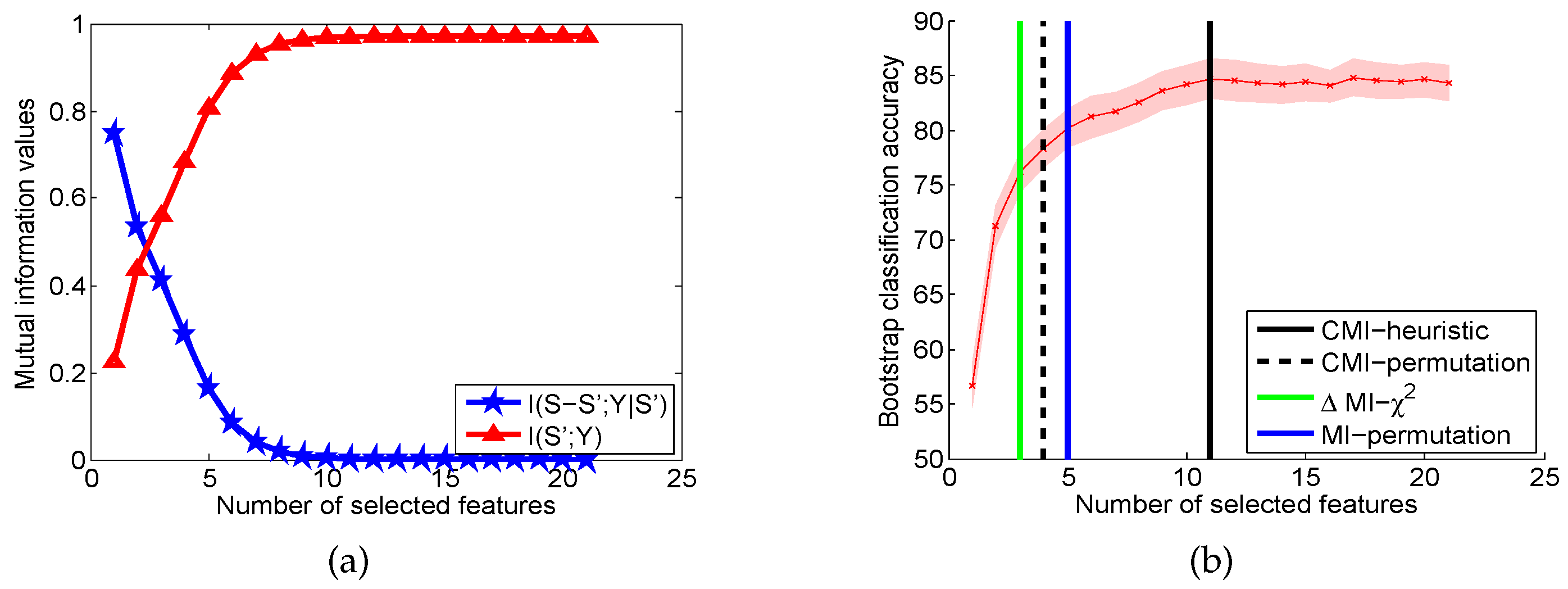
We compared our two criteria with existing ones [14,19] on 10 well-known public datasets used in previous feature selection research [8,19], covering a wide variety of sample-feature ratios and a range of multiclass problems. The detailed properties of these datasets, including the number of features (F), the number of examples (N), and the number of classes (C), are available in Reference [8]. We refer the criterion in Reference [19] -, since it monitors the increment of MI (i.e., ) with distribution. We refer the criterion in Reference [14] MI-permutation, since it uses the permutation test to quantify the impact of on . Throughout this paper, we selected in CMI-heuristic and used the multivariate matrix-based Rényi’s -entropy functional to estimate all MI quantities in MI-permutation. The baseline information feature selection method used in this paper is from Reference [13], which directly optimizes in a greedy manner without any decomposition or approximation. An example for different stopping criteria on the dataset waveform is shown in Figure 1.
To provide a comprehensive evaluation, we tested the performance of the novel Rényi’s -entropy estimator with (to approximate Shannon’s definition) and (i.e., the quadratic information quantities that have been widely applied in information theoretic learning [26]). Moreover, we also tested the performance of different statistical tests with significance level and , but since the results are very similar, herein, we only report results with . The quantitative results, under different values of , are summarized in Table 1 and Table 2. For each criterion, we reported the number of selected features and the average classification accuracy across 100 bootstrap runs. In each run, N bootstrap samples are drawn for the training set, while the unselected samples serve as the test set. Same as in Reference [8], we used the linear support vector machine (SVM) [32] as the baseline classifier. To give a reference, we defined the “optimal” number of features (an unknown parameter) as the one that yields the maximum bootstrap accuracy or first achieves a bootstrap accuracy with no statistical difference to the maximum value (evaluated by paired t-test with significance level ), and ranked all the criteria based on the difference between their estimated number of features and the optimal one.
As can be seen, - is likely to severely underestimate the number of features, accompanied by the lowest bootstrap accuracy. One possible reason is that does not precisely fit a distribution if the MB condition is not satisfied. CMI-permutation and MI-permutation always have the same ranks. This is because , a fixed value. Thus, it is equivalent to monitor the increment of or the decrement of . On the other hand, it is surprising to find that CMI-heuristic performs the best in most datasets. This indicates that although the permutation test is effective to test the MB condition, is a reliable threshold to speed up this test, as the permutation test is always time-consuming. If we look deeper, it is also interesting to see that different values of in Rényi’s entropy affect the results. This is to be expected, because the is associated with the norm selected in the simplex to find the distance of the PDF to the center of the space. Effectively. different weights change the effects of the tails, as explained in Reference [26]: Values of smaller than 1 emphasize the importance of samples in the tails, values larger than 2 emphasize the modes of the distributions, whereas values close to 2 give equal weights to every sample, no matter where it is located in the distribution. Since classification uses a counting norm, values of lower than 2 should be preferred. This is also the reason CMI-permutation and MI-permutation perform better with . Finally, the Wilcoxon rank-sum test at significance level, shown in Table 3, corroborates our analysis that our criteria perform equally to or slightly better than MI-permutation, but significantly better than -.
4. Conclusions
This paper suggests two simple stopping criteria, namely, CMI-heuristic and CMI-permutation, for information theoretic feature selection by monitoring the value of CMI estimated with the novel multivariate matrix-based Rényi’s -entropy functional. Experiments on 10 benchmark datasets indicate that (1) CMI is a more tractable quantity than MI, and (2) the non-parametric test (like the permutation test) is more effective than the parametric test with a prior distribution (like the distribution), to guide early stopping in feature selection. Moreover, as an alternative to a permutation test, we also demonstrate a tiny threshold is sufficient to test the MB condition, which is very valuable for practitioners across different domains.
In the future, we will investigate the performance of our stopping criteria on big data. This is because with the tremendous growth of dataset sizes and dimensionality, the scalability of most feature selection methods could be jeopardized [33]. This problem is particularly important for our criteria, as the large-scale eigenvalue decomposition is always a challenging problem mathematically [34]. Moreover, we are also interested in testing our criteria on different types of data, including the linked data that is pervasive in social media and bioinformatics [33].
Author Contributions
Methodology, S.Y. and J.C.P.; software, S.Y.; investigation, S.Y. and J.C.P.; writing—original draft preparation, S.Y.; writing—review and editing, S.Y. and J.C.P.; supervision, J.C.P.; funding acquisition, J.C.P.
Funding
This research was funded by the U.S. Office of Naval Research under grant number N00014-15-1-2103 and N00014-18-1-2306.
Acknowledgments
The authors thank the reviewers for their very helpful suggestions, which led to substantial improvements of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MI | Mutual information |
| CMI | Conditional mutual information |
| RKHS | Reproducing kernel Hilbert space |
| MB | Markov blanket |
| Probability density function |
References
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Lu, Y.; Fan, Y.; Lv, J.; Noble, W.S. DeepPINK: Reproducible feature selection in deep neural networks. In Proceedings of the 2018 Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 8690–8700. [Google Scholar]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meyer, P.E.; Schretter, C.; Bontempi, G. Information-theoretic feature selection in microarray data using variable complementarity. IEEE J. Sel. Top. Signal Process. 2008, 2, 261–274. [Google Scholar] [CrossRef]
- Gurban, M.; Thiran, J.P. Information theoretic feature extraction for audio-visual speech recognition. IEEE Trans. Signal Process. 2009, 57, 4765–4776. [Google Scholar] [CrossRef]
- Eriksson, T.; Kim, S.; Kang, H.G.; Lee, C. An information-theoretic perspective on feature selection in speaker recognition. IEEE Signal Process. Lett. 2005, 12, 500–503. [Google Scholar] [CrossRef]
- Brown, G.; Pocock, A.; Zhao, M.J.; Luján, M. Conditional likelihood maximisation: a unifying framework for information theoretic feature selection. J. Mach. Learn. Res. 2012, 13, 27–66. [Google Scholar]
- Fleuret, F. Fast binary feature selection with conditional mutual information. J. Mach. Learn. Res. 2004, 5, 1531–1555. [Google Scholar]
- Ross, B.C. Mutual information between discrete and continuous data sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef]
- Singha, S.; Shenoy, P.P. An adaptive heuristic for feature selection based on complementarity. Mach. Learn. 2018, 107, 1–45. [Google Scholar] [CrossRef]
- Vinh, N.X.; Zhou, S.; Chan, J.; Bailey, J. Can high-order dependencies improve mutual information based feature selection? Pattern Recognit. 2016, 53, 46–58. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Giraldo, L.G.S.; Jenssen, R.; Principe, J.C. Multivariate Extension of Matrix-based Renyi’s α-order Entropy Functional. arXiv, 2018; arXiv:1808.07912. [Google Scholar]
- François, D.; Rossi, F.; Wertz, V.; Verleysen, M. Resampling methods for parameter-free and robust feature selection with mutual information. Neurocomputing 2007, 70, 1276–1288. [Google Scholar] [CrossRef] [Green Version]
- Gómez-Verdejo, V.; Verleysen, M.; Fleury, J. Information-theoretic feature selection for the classification of hysteresis curves. In International Work-Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, German, 2007; pp. 522–529. [Google Scholar]
- Koller, D.; Sahami, M. Toward Optimal Feature Selection; The Stanford University InfoLab: Stanford, CA, USA, 1996. [Google Scholar]
- Yaramakala, S.; Margaritis, D. Speculative Markov blanket discovery for optimal feature selection. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; pp. 809–812. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Vinh, N.X.; Chan, J.; Bailey, J. Reconsidering Mutual Information Based Feature Selection: A Statistical Significance View. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence (AAAI’14), Quebec City, QC, Canada, 27–31 July 2014; pp. 2092–2098. [Google Scholar]
- Good, P. Permutation Tests: A Practical Guide to Resampling Methods for Testing Hypotheses; Springer: Berlin/Heidelberg, German, 2013. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Campos, L.M. A scoring function for learning Bayesian networks based on mutual information and conditional independence tests. J. Mach. Learn. Res. 2006, 7, 2149–2187. [Google Scholar]
- Giraldo, L.G.S.; Rao, M.; Principe, J.C. Measures of entropy from data using infinitely divisible kernels. IEEE Trans. Inf. Theory 2015, 61, 535–548. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rényi, A. On Measures of Entropy and Information; Hungarian Academy of Sciences: Budapest, Hungary, 1961. [Google Scholar]
- Principe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Pperspectives; Springer: Berlin/Heidelberg, German, 2010. [Google Scholar]
- Ohya, M.; Petz, D. Quantum Entropy and Its Use; Springer: Berlin/Heidelberg, German, 2004. [Google Scholar]
- Bhatia, R. Infinitely divisible matrices. Am. Math. Mon. 2006, 113, 221–235. [Google Scholar] [CrossRef]
- Müller-Lennert, M.; Dupuis, F.; Szehr, O.; Fehr, S.; Tomamichel, M. On quantum Rényi entropies: A new generalization and some properties. J. Math. Phys. 2013, 54, 122203. [Google Scholar] [CrossRef]
- Mosonyi, M.; Hiai, F. On the Quantum Rényi Relative Entropies and Related Capacity Formulas. IEEE Trans. Inf. Theory 2011, 57, 2474–2487. [Google Scholar] [CrossRef]
- Verdú, S. α-mutual information. In Proceedings of the 2015 IEEE Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 1–6 February 2015; pp. 1–6. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Li, J.; Liu, H. Challenges of feature selection for big data analytics. IEEE Intell. Syst. 2017, 32, 9–15. [Google Scholar] [CrossRef]
- Martin, C.D.; Porter, M.A. The extraordinary SVD. Am. Math. Mon. 2012, 119, 838–851. [Google Scholar] [CrossRef]
Figure 1.
(a) shows the the values of mutual information (MI) and conditional mutual information (CMI) with respect to different number of selected features, i.e., the size of . is monotonically increasing, whereas is monotonically decreasing. (b) shows the terminated points produced by different stopping criteria, namely CMI-heuristic (black solid line), CMI-permutation (black dashed line), - (green solid line), and MI-permutation (blue solid line). The red curve with the shaded area indicates the average bootstrap classification accuracy with confidence interval. In this example, the bootstrap classification accuracy reaches its statistical maximum value with 11 features and CMI-heuristic performs the best.
Figure 1.
(a) shows the the values of mutual information (MI) and conditional mutual information (CMI) with respect to different number of selected features, i.e., the size of . is monotonically increasing, whereas is monotonically decreasing. (b) shows the terminated points produced by different stopping criteria, namely CMI-heuristic (black solid line), CMI-permutation (black dashed line), - (green solid line), and MI-permutation (blue solid line). The red curve with the shaded area indicates the average bootstrap classification accuracy with confidence interval. In this example, the bootstrap classification accuracy reaches its statistical maximum value with 11 features and CMI-heuristic performs the best.


{kind=link}
Table 1.
The number of selected features (#F) and the bootstrap classification accuracy (acc.) comparison for CMI-heuristic and CMI-permutation against different stopping criteria. We set for Rényi’s -entropy functional. All criteria are ranked based on the difference between their selected number of features and the optimal values. The best two ranks are marked with green and blue, respectively. The average rank across all datasets is reported in the bottom line. The value behind the name of each dataset indicates the total number of features.
Table 1.
The number of selected features (#F) and the bootstrap classification accuracy (acc.) comparison for CMI-heuristic and CMI-permutation against different stopping criteria. We set for Rényi’s -entropy functional. All criteria are ranked based on the difference between their selected number of features and the optimal values. The best two ranks are marked with green and blue, respectively. The average rank across all datasets is reported in the bottom line. The value behind the name of each dataset indicates the total number of features.
| CMI-Heuristic | CMI-Permutation | MI- [19] | MI-Permutation [14] | “Optimal” | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #F | acc. | rank | #F | acc. | rank | #F | acc. | rank | #F | acc. | rank | #F | acc. | |
| waveform (21) | 11 | 84.7 ± 1.8 | 1 | 4 | 78.3 ± 1.8 | 3 | 3 | 76.1 ± 1.8 | 4 | 5 | 80.2 ± 1.8 | 2 | 11 | 84.7 ± 1.8 |
| breast (30) | 2 | 92.3 ± 1.7 | 1 | 2 | 92.3 ± 1.7 | 1 | 2 | 92.3 ± 1.7 | 1 | 2 | 92.3 ± 1.7 | 1 | 2 | 95.2 ± 1.2 |
| heart (13) | 13 | 81.7 ± 3.5 | 4 | 4 | 80.4 ± 3.3 | 1 | 2 | 76.9 ± 3.8 | 3 | 4 | 80.4 ± 3.3 | 1 | 6 | 82.6 ± 3.0 |
| spect (22) | 22 | 80.6 ± 3.6 | 4 | 11 | 82.1 ± 3.3 | 1 | 1 | 80.1 ± 3.3 | 3 | 7 | 81.1 ± 3.3 | 2 | 11 | 82.1 ± 3.3 |
| ionosphere (34) | 15 | 83.3 ± 2.8 | 1 | 7 | 81.8 ± 2.8 | 2 | 1 | 76.7 ± 3.2 | 4 | 7 | 81.8 ± 2.8 | 2 | 33 | 85.3 ± 3.0 |
| parkinsons (22) | 12 | 85.2 ± 3.7 | 1 | 4 | 85.0 ± 3.2 | 2 | 1 | 85.1 ± 3.5 | 4 | 4 | 85.0 ± 3.2 | 2 | 9 | 86.5 ± 3.4 |
| semeion (256) | 59 | 86.1 ± 1.3 | 1 | 20 | 77.7 ± 1.5 | 2 | 4 | 49.6 ± 1.7 | 4 | 20 | 77.7 ± 1.5 | 2 | 73 | 93.3 ± 1.3 |
| Lung (325) | 5 | 74.2 ± 7.7 | 3 | 10 | 73.9 ± 8.0 | 2 | 1 | 46.5 ± 7.5 | 4 | 13 | 79.1 ± 7.9 | 1 | 41 | 84.3 ± 6.5 |
| Lympth (4026) | 6 | 81.3 ± 5.8 | 1 | 248 | 88.7 ± 6.1 | 3 | 2 | 62.8 ± 6.5 | 2 | 249 | 88.9 ± 6.2 | 4 | 70 | 90.7 ± 5.4 |
| Madelon (500) | 3 | 69.5 ± 1.6 | 2 | 2 | 59.5 ± 1.6 | 3 | 4 | 76.7 ± 1.5 | 1 | 2 | 59.5 ± 1.6 | 3 | 4 | 76.7 ± 1.5 |
| average rank | 1.9 | 2.0 | 3.0 | 2.0 | ||||||||||
Table 2.
The number of selected features (#F) and the bootstrap classification accuracy (acc.) comparison for CMI-heuristic and CMI-permutation against different stopping criteria. We set for Rényi’s -entropy functional. All criteria are ranked based on the difference between their selected number of features and the optimal values. The best two ranks are marked with green and blue, respectively. The average rank across all datasets is reported in the bottom line. The value behind the name of each dataset indicates the total number of features.
Table 2.
The number of selected features (#F) and the bootstrap classification accuracy (acc.) comparison for CMI-heuristic and CMI-permutation against different stopping criteria. We set for Rényi’s -entropy functional. All criteria are ranked based on the difference between their selected number of features and the optimal values. The best two ranks are marked with green and blue, respectively. The average rank across all datasets is reported in the bottom line. The value behind the name of each dataset indicates the total number of features.
| CMI-Heuristic | CMI-Permutation | MI- [19] | MI-Permutation [14] | “Optimal” | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #F | acc. | rank | #F | acc. | rank | #F | acc. | rank | #F | acc. | rank | #F | acc. | |
| waveform (21) | 17 | 84.2 ± 1.9 | 1 | 4 | 78.2 ± 2.1 | 2 | 3 | 76.1 ± 2.0 | 4 | 4 | 78.2 ± 2.1 | 2 | 11 | 84.7 ± 1.8 |
| breast (30) | 1 | 90.9 ± 1.5 | 2 | 1 | 90.9 ± 1.5 | 2 | 2 | 95.2 ± 1.2 | 1 | 1 | 90.9 ± 1.5 | 2 | 2 | 95.2 ± 1.2 |
| heart (13) | 6 | 82.6 ± 3.0 | 1 | 1 | 55.0 ± 4.4 | 3 | 2 | 76.9 ± 3.8 | 2 | 1 | 55.0 ± 4.4 | 3 | 6 | 82.6 ± 3.0 |
| spect (22) | 17 | 80.2 ± 4.2 | 1 | 2 | 78.2 ± 3.2 | 3 | 1 | 79.6 ± 3.2 | 4 | 3 | 79.1 ± 3.2 | 2 | 11 | 81.4 ± 4.2 |
| ionosphere (34) | 18 | 84.7 ± 2.9 | 1 | 8 | 81.9 ± 3.5 | 2 | 1 | 76.4 ± 3.9 | 4 | 8 | 81.9 ± 3.5 | 2 | 33 | 85.3 ± 3.0 |
| parkinsons (22) | 13 | 83.7 ± 3.7 | 1 | 4 | 84.6 ± 3.2 | 2 | 1 | 77.0 ± 5.0 | 4 | 3 | 84.6 ± 3.4 | 3 | 9 | 86.0 ± 3.9 |
| semeion (256) | 53 | 85.5 ± 1.1 | 1 | 40 | 82.7 ± 1.4 | 2 | 4 | 49.6 ± 1.7 | 4 | 40 | 82.7 ± 1.4 | 2 | 73 | 93.3 ± 1.3 |
| Lung (325) | 9 | 76.1 ± 7.9 | 2 | 5 | 74.2 ± 7.7 | 3 | 1 | 46.5 ± 7.5 | 4 | 11 | 73.0 ± 7.1 | 1 | 41 | 84.3 ± 6.5 |
| Lympth (4026) | 8 | 86.0 ± 5.3 | 3 | 65 | 89.6 ± 5.5 | 1 | 2 | 62.8 ± 6.5 | 4 | 64 | 89.6 ± 5.5 | 2 | 70 | 90.7 ± 5.4 |
| Madelon (500) | 3 | 69.5 ± 1.6 | 2 | 1 | 52.4 ± 1.7 | 3 | 4 | 76.7 ± 1.5 | 1 | 1 | 52.4 ± 1.7 | 3 | 4 | 76.7 ± 1.5 |
| average rank | 1.5 | 2.3 | 3.2 | 2.2 | ||||||||||
Table 3.
Summary of p-values and decisions (in parentheses) of Wilcoxon rank-sum test at significance level on ranks of our criteria against MI- and MI-permutation. A p-value smaller than indicates rejection of the null hypothesis that two criteria perform equally.
Table 3.
Summary of p-values and decisions (in parentheses) of Wilcoxon rank-sum test at significance level on ranks of our criteria against MI- and MI-permutation. A p-value smaller than indicates rejection of the null hypothesis that two criteria perform equally.
| MI- | MI-Permutation | |
| CMI-heuristic | 0.0781 (1) | 0.5455 (0) |
| CMI-permutation | 0.0561 (1) | 0.9036 (0) |
| MI- | MI-Permutation | |
| CMI-heuristic | 0.0081 (1) | 0.0341 (1) |
| CMI-permutation | 0.0587 (1) | 0.7340 (0) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yu, S.; Príncipe, J.C. Simple Stopping Criteria for Information Theoretic Feature Selection. Entropy 2019, 21, 99. https://doi.org/10.3390/e21010099
AMA Style
Yu S, Príncipe JC. Simple Stopping Criteria for Information Theoretic Feature Selection. Entropy. 2019; 21(1):99. https://doi.org/10.3390/e21010099
Chicago/Turabian StyleYu, Shujian, and José C. Príncipe. 2019. "Simple Stopping Criteria for Information Theoretic Feature Selection" Entropy 21, no. 1: 99. https://doi.org/10.3390/e21010099
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.