
Inconsistency of Template Estimation by Minimizing of the Variance/Pre-Variance in the Quotient Space †

1
Université Côte d’Azur, Inria, France
2
INSERM, UMRS 1138, CRC, team 22, Paris Descartes University, UPMC, Paris, France
3
CMLA, ENS Cachan, CNRS, Université Paris-Saclay, 94235 Cachan, France
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our paper published in Information Processing in Medical Imaging 2017, Boone, NC, USA, 25–30 June 2017.
Entropy 2017, 19(6), 288; https://doi.org/10.3390/e19060288
Submission received: 27 April 2017
/
Revised: 7 June 2017
/
Accepted: 17 June 2017
/
Published: 20 June 2017
(This article belongs to the Special Issue Information Geometry II)
Abstract
:We tackle the problem of template estimation when data have been randomly deformed under a group action in the presence of noise. In order to estimate the template, one often minimizes the variance when the influence of the transformations have been removed (computation of the Fréchet mean in the quotient space). The consistency bias is defined as the distance (possibly zero) between the orbit of the template and the orbit of one element which minimizes the variance. In the first part, we restrict ourselves to isometric group action, in this case the Hilbertian distance is invariant under the group action. We establish an asymptotic behavior of the consistency bias which is linear with respect to the noise level. As a result the inconsistency is unavoidable as soon as the noise is enough. In practice, template estimation with a finite sample is often done with an algorithm called “max-max”. In the second part, also in the case of isometric group finite, we show the convergence of this algorithm to an empirical Karcher mean. Our numerical experiments show that the bias observed in practice can not be attributed to the small sample size or to a convergence problem but is indeed due to the previously studied inconsistency. In a third part, we also present some insights of the case of a non invariant distance with respect to the group action. We will see that the inconsistency still holds as soon as the noise level is large enough. Moreover we prove the inconsistency even when a regularization term is added.
1. Introduction
1.1. General Introduction
Template estimation is a well known issue in different fields such as statistics on signals [1], shape theory, computational anatomy [2,3,4] etc. In these fields, the template (which can be viewed as the prototype of our data) can be (according to different vocabulary) shifted, transformed, wrapped or deformed due to different groups acting on data. Moreover, due to a limited precision in the measurement, the presence of noise is almost always unavoidable. These mixed effects on data lead us to study the consistency of algorithms which claim to compute the template. A popular algorithm consists in the minimization of the variance, in other words, the computation of the Fréchet mean in quotient space. This method has been already proved to be inconsistent [5,6,7]. In [5] the authors proves the inconsistency with a lower bound of the expectation of the error between the original template and the estimated template with a finite sample, they deduce that this expectation does not go to zero as the size of the sample goes to infinity. This work was done in a functional space, where functions only observed at a finite number of points of the functions were observed. In this case one can model these observable values on a grid. When the resolution of the grid goes to zero, one can show the consistency [8] by using the Fréchet mean with the Wasserstein distance on the space of measures rather than in the space of functions. However, in (medical) images the number of pixels or voxels is finite.
In [6], the authors demonstrated the inconsistency in a finite dimensional manifold with Gaussian noise, when the noisel level tends to zero. In our previous work [7], we focused our study on the inconsistency with Hilbert Space (including infinite dimensional case) as ambient space. This current paper is an extension of a conference paper [9].
1.2. Why Using a Group Action? Comparison with the Standard Norm
In the following, we take a simple example which justifies the use of the group action in order to compare the shape of two functions:
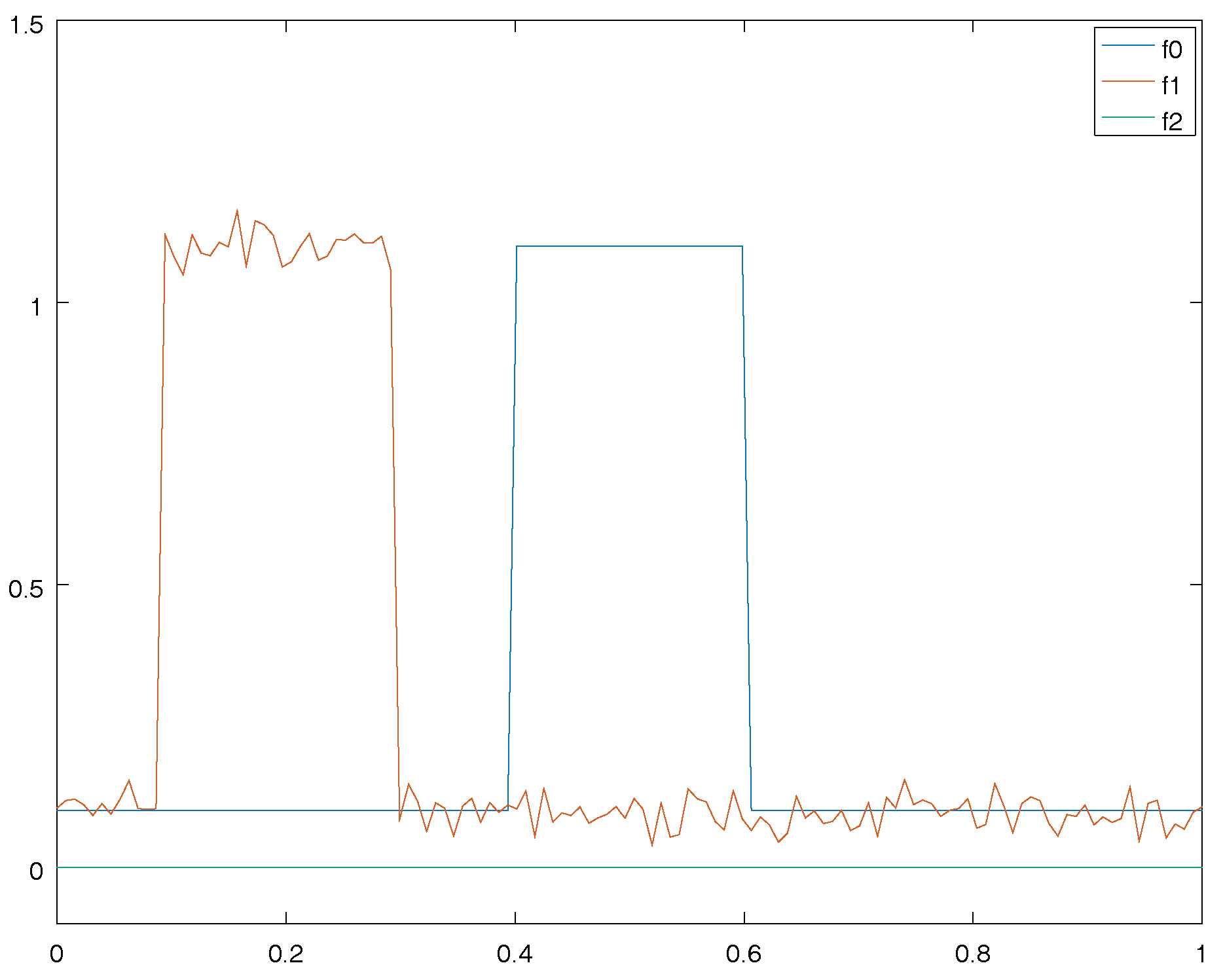
On Figure 1, suppose that you want to compare these functions. The simplest way to compare with would be to compute the -norm (or any other norm) of − , if we do that we have that . Likewise , therefore the norm tells us that is at the same distance from and from . Yet, our eyes would say that , have the same shape, contrarily to and . Therefore the simple use of the -norm in the space of functions is not enough. To have a relevant way to compare functions, one can register functions first. Firstly, we estimate the better time translation which aligns and and secondly, we compute the -norm after this alignment step. On this example, we find that the distance is now ≃0.02. On the contrarily, after alignment the distance between and is still ≃0.6. With this new way of comparing functions, the functions looks like but do not look like . This fits with our intuition. That is why we use a group action in order to perform statistics. In the following paragraph, we precise how to do it in general.
This idea of using deformations/transformation in order to compare things is not new. It was already proposed by Darcy Thompson [10] in the beginning of the 20th century, in order to classify species.
1.3. Settings and Notation
In this paper, we suppose that observations belong to a Hilbert space , we denote by the norm associated to the dot product . We also consider a group of transformation G which acts on M the space of observations. This means that and for all , , where e is the identity element of G. Note that in this article, is the result of the action of g on x, and · should not to be confused with the multiplication of real numbers noted ×.
The generative model is the following: we transform an unknown template with a random and unknown element of the group G and we add some noise. Let be a positive noise level and a standardized noise: , . Moreover we suppose that and are independent random variables. Finally, the only observable random variable is:
This generative model is commonly used in Computational anatomy in diverse frameworks, for instance with currents [11,12], varifolds [13], LDDMM on images [14] but also in functional data analysis [1]. All these works are applied in different spaces, for instance, the varifold builds an embedding of the surfaces into an Hilbert space, and a group of diffeomorphisms have the ability of deform these surfaces. Supposing a general group action on a space with the generative model (1) allows us to embed all these various situations into one abstract model, and to study template estimation in this abstract model.
Example of noise: if we assume that the noise is independent and identically distributed on each pixel or voxel with a standard deviation w, then , where N is the number of pixels/voxels. However, the noise which we consider can be more general: we do not require the fact that the noise is independent over each region of the space M.
Note that the inconsistency of Template estimation can be also studied with an alternative generative model, called backward model where [7]. Some authors also use the term perturbation model see [15,16,17].
Quotient space: the random transformation of the template by the group leads us to project the observation Y into the quotient space. The quotient space is defined as the set containing all the orbit for . The set which is constituted of all orbits is call the quotient space M by the group G and is noted by:
As we want to do statistics on this space, we aim to equip the quotient with a metric. One often requires that the distance in the ambient space is invariant under the group action G, this means that
If is invariant and if the orbits are closed sets (if the orbits are not closed sets, it is possible to have even if , in this case we call a pseudo-distance. Nevertheless, this has no consequence in this paper if is only a pseudo-distance), then
is well defined, and is a distance in the quotient space. The quotient distance is the distance between x and where is the registration of y with respect to x. We say in this case that is in optimal position with respect to x.
One particular distance in the ambient space M, which we use in all this article, is the distance given by the norm of the Hilbert space: . Moreover we say that G acts isometrically on M, if is a linear map which leaves the norm unchanged. In this case the distance given by the norm of the Hilbert space is invariant under the group action. The quotient (pseudo)-distance is, in this case (see Figure 2), .
Remark 1.
When G acts isometrically on M a Hilbert space, by expansion of the squared norm we have:
Thus, even if the quotient space is not a linear space, we have a “polarization identity” in the quotient space:
When the distance given by the norm is invariant under the group action, we define the variance of the random orbit as the expectation of the (pseudo)-distance between the random orbit and the orbit of a point x in M:
Note that is well defined for all because is finite. Moreover, since , for all and , the variance F is well defined in the quotient space: does have a sense.
Moreover, in presence of a sample of the observable variable Y noted , one can define the empirical variance of a point x in M:
Definition 1.
Template estimation is performed by minimizing :
In order to study this estimation method, one can look the limit of this estimator when the number of data n tends to , in this case, the estimation becomes:
If minimizes F, then is called a Fréchet mean of .
Definition 2.
We say that the estimation is consistent if minimizes F. Moreover the consistency bias, noted , is the (pseudo)-distance between the orbit of the template and : . If such a does not exist, then the consistency bias is infinite.
Note that, if the action is not isometric and is not either invariant, a priori is no longer a (pseudo)-distance in the quotient space (this point is discussed in Section 3). However one can still define F and wonder if the minimization of F is a consistent estimator of . In this case, we call F a pre-variance.
1.4. Questions and Contributions
This setting leads us to wonder about few things listed below:
Questions:
- Is a minimum of the variance or the pre-variance?
- What is the behavior of the consistency bias with respect to the noise level?
- How to perform such a minimization of the variance? Indeed, in practice we have only a sample and not the whole distribution.
Contribution: In the case of an isometric action, we provide a Taylor expansion of the consistency bias when the noise level tends to infinity. As we do not have the whole distribution, we minimize the empirical variance given a sample. An element which minimizes this empirical variance is called an empirical Fréchet mean. We already know that the empirical Fréchet mean converges to the Fréchet mean when the sample size tends to infinity [18]. Therefore our problem is reduced to finding an empirical Fréchet mean with a finite but sufficiently large sample. One algorithm called the “max-max” algorithm [19] aims to compute such an empirical Fréchet mean. We establish some properties of the convergence of this algorithm. In particular, when the group is finite, the algorithm converges in a finite number of steps to an empirical Karcher mean (a local minimum of the empirical variance given a sample). This helps us to illustrate the inconsistency in this very simple framework.
We would like to insist on this point: the noise is created in the ambient space with our generative model and the computation of the Fréchet mean is done in the quotient space, this interaction induces an inconsistency. On the opposite, if one models the noise directly in the quotient space and compute the Fréchet mean in the quotient space, we have no reason to suspect any inconsistency.
Moreover it is also possible to define and use isometric actions on curves [1,20] or on surfaces [21] where our work can be directly applied. The previous works related to the inconsistency of template estimation [5,6,7] focused on isometric action, which is a restriction to real applications. That is why we provide, in Section 3, some insights of the non invariant case: the inconsistency also appears as soon as the noise level is large enough.
This article is organized as follows: Section 2 is dedicated for isometric action. More precisely, in Section 2.2, we study the presence of the inconsistency and we establish the asymptotic behavior when the noise parameter tends to ∞. In Section 2.4 we detail the max-max algorithm and its properties. In Section 2.5 we illustrate the inconsistency with synthetic data. Finally in Section 3, we prove the inconsistency for more general group action, when the noise level is large enough. We do it in two settings, the first one is that the group contains a subgroup acting isometrically on M, the second one is that the group acts linearly on the space M.
2. Inconsistency of Template Estimation with an Isometric Action
2.1. Congruent Section and Computation of Fréchet Mean in Quotient Space
Given points m and y, there is a priori no closed formed expression in order to compute the quotient distance . Therefore computing and minimizing the variance in the quotient does not seem straightforward. There is one case where it may be possible: the existence of a congruent section. We say that is a section if , where is the canonical projection into the quotient space. Moreover we say that the section s is congruent if:
Then the image of the quotient by the section is a part of M which has an interesting property:
In other words, the section gives us a part of M containing a point of each orbit such that all points in are already registered. Moreover, if s is a section, is also a section, without loss of generality we can assume that .
In this case, the variance is equal to:
where we recognize the variance of the random variable . As we know that the element which minimizes the variance in a linear space is given by the expected value, we have that:
Moreover this inequality is strict if and only if m and are not in the same orbit.
Therefore, we have a method in order to know if the estimation is consistent or not: computing and verifying if and are in the same orbit, and the consistency bias is given by . Moreover if we take , we have and it is now straightforward that the restriction of F to is differentiable on (we say that is differentiable on , even if is not open, because is defined and differentiable on M, and is equal to ), and that in particular gives us the value of the bias.
Example 1.
The action of rotations: acts isometrically on . We notice that the quotient distance is . We can check that is a section for v an unitary vector. Therefore the computation of the bias is given by .
Unfortunately, the congruent section generally does not exist. Let us give an example:
Example 2.
Taking with , we consider the action of on by time translation, for , and :
where indexes are taken modulo N. If we take , , . By hand we can check that there is no , and such that , , and . Thus, a congruent section in does not exists.
We can generalize this simple example by taking a non finite group:
Example 3.
Let us take the set of 1-periodic functions such that . acts on by time translation defined by:
Then a section in does not exists.
Proof.
Let us take , and for some (see Figure 3). Let us suppose that a section s exists, then without loss of generality we can assume that , then we should have in other words, should be registered with respect to . For we can verify that and that this inequality is strict as soon as . Then is the only element of registered with then . Likewise for , then we should have:
However it is easy to verify that . This is a contradiction. Therefore, a congruent section does not exist. ☐
When the congruent section exists, then the quotient can be included in a part of the ambient space M and the metric and are corresponding. The existence of a congruent section indicates us that the quotient space is not so complicated. Indeed when there is an existence of a congruent section, the quotient space is embedded in the ambient space with respect to the distances in the quotient space and in the ambient space. In that case computations are easier, projecting data on this part S and taking the mean. Then when such a congruent section does not exist, computing the Fréchet mean in quotient space is not so obvious. However, we can established proofs of inconsistency which are less tight. In this article we prove that the method is inconsistent when the noise is large.
2.2. Inconsistency and Quantification of the Consistency Bias
We start with Theorem 1 which gives us an asymptotic behavior of the consistency bias when the noise level tends to infinity. One key notion in Theorem 1 is the concept of fixed point under the action G: a point is a fixed point if for all . We require that the support of the noise is not included in the set of fixed points. However, this condition is almost always fulfilled. For instance in the set of fixed points under a linear group action is a null set for the Lebesgue measure (unless the action is trivial: for all but this situation is irrelevant).
Theorem 1.
Let us suppose that the support of the noise ϵ is not included in the set of fixed points under the group action. Let Y be the observable variable defined in Equation (1). If the Fréchet mean of exists, then we have the following lower and upper bounds of the consistency bias noted CB:
where , K is a constant which depends only of the standardized noise and of the group action. The consistency bias has the following asymptotic behavior when the noise level σ tends to infinity:
In the following we note by S the unit sphere of M. For , we call , so that . The sketch of the proof is the following:
- because the support of is not included in the set of fixed points under the action of G.
- is the consequence of the Cauchy-Schwarz inequality.
- The proof of Inequalities (3) is based on the triangular inequalities:where minimizes F: having a piece of information about the norm of is enough to deduce a piece of information about the consistency bias.
Proof of Theorem 1.
We note S the unit sphere in M. In order to prove that , we take x in the support of such that x is not a fixed point under the action of G. It exists such that . We note , we have and by continuity of the dot product it exists such that: as x is in the support of we have , it follows:
Thanks to Inequality (5) and the fact that we have:
Then we get . Moreover, if we use the Cauchy-Schwarz inequality:
In order to prove Inequalities (3), we use the “polar” coordinates of a point in M (see Figure 4), every point in M can be represented by where is the radius, and v belong to S the unit sphere in M, v represents the “angle”. We compute as a function of . In a first step, we minimize this expression as a function of r, in a second step we minimize this expression as a function of v. This makes appear the constant K. As we said, let us take and , we expand the variance at the point :
Indeed thanks to the isometric action. We note the positive part of x. Moreover we define the two following functions:
since that reaches its minimum at the point and , the which minimizes (6) is and the minimum value of the variance restricted to the half line is:
To find the Fréchet mean of , we need to maximize with respect to :
Note that we remove the positive part and the square because indeed takes a non negative value. In order to prove it let us remark that:
then there is two cases: if then for any we have , if then we take , and we get .
As we said in the sketch of the proof we are interested in getting information about the norm of :
Let , we have: because the action is isometric. Now we decompose and we get:
By taking the largest value in these inequalities with respect to , we get by definition of K:
Moreover we recall the triangular inequalities:
2.3. Remarks about Theorem 1 and Its Proof
We can ensure the presence of inconsistency as soon as the signal to noise ratio satisfies . Moreover, if the signal to noise ratio verifies then the consistency bias is not smaller than i.e., . In other words, the Fréchet mean in quotient space is too far from the template: the template estimation with the Fréchet mean in quotient space is useless in this case. In [7] we also gave lower and upper bounds as a function of but these bounds were less informative than bounds given by Theorem 1. These bounds did not give the asymptotic behaviour of the consistency bias. Moreover, in [7] the lower bound goes to zero when the template becomes closed to fixed points. This may suggest that the consistency bias was small for this kind of template. We prove here that it is not the case.
Note that Theorem 1 is not a contradiction with [1] where the authors proved the consistency of template estimation with the Fréchet mean in quotient space for all . Indeed their noise was included in the set of constant functions which are the fixed points under their group action.
The constant K appearing in the asymptotic behaviour of the consistency bias (4) is a constant of interest. We can give several (but similar) interpretations of K:
- It follows from Equation (3) that K is the consistency bias with a null template and a standardized noise ().
- From the proof of Theorem 1 we know that . On the one hand, if G is the group of rotations then , because for all v s.t. , , by aligning v and . On the other hand if G acts trivially (which means that for all ) then . The general case for K is between two extreme cases: the group where the orbits are minimal (one point) and the group for which the orbits are maximal (the whole sphere). We can state that the more the group action has the ability to align the elements, the larger the constant K is and the larger the consistency bias is.
- The squared quotient distance between two points is:thus the larger , the smaller . , encodes the level of contraction of the quotient distance (or folding). The larger K is, the more contracted the quotient space is.
One disadvantage of Theorem 1 is that it ensures the presence of inconsistency for large enough but it says nothing when is small, in this case one can refer to [6] or [7].
We can remark that this Theorem can be used as an alternating proof the following Theorem (which was already proved in [7]), proving and quantifying inconsistency when the template is a fixed point:
Corollary 1.
Let G acting isometrically on M an Hilbert space. Let be a fixed point, and ϵ a standardized noise which support is not included in the set of fixed points. Then estimating the template with the Fréchet mean is inconsistent. Moreover if the Fréchet mean in quotient space exists then the consistency bias is equal to:
Indeed for which is a particular fixed point we have thanks to Theorem 1. If is a fixed point non necessarily equal to 0, we can define , in this random variable 0 is the template we can apply the formula to the random variable , which concludes.
In the proof of Theorem 1, we have seen that the minimum of the variance restricted to the half-line for , was
therefore is a registration score: tells you how much it is a good idea to search the Fréchet mean of in the direction pointed by v: the more is large, the more v is a good choice. On the contrary when this value is equal to zero, it is useless to search the Fréchet mean in this direction.
Likewise, for , is a registration score with respect to the noise, the larger , the more the unit vector v looks like to the noise after registration.
If is a Fréchet mean of we have seen that its norm verifies:
Then if there is two different Fréchet means of noted and , we can deduce that . Even if there is no uniqueness of the Fréchet mean in the quotient space, we can state that the representants of the different Fréchet means have all the same norm.
Remark 2.
We can also wonder if the converse of Theorem 1 is true: if ϵ is a non biased noise always included in the set of fixed point, is a Fréchet mean of ? A simple computation show that is a minimum of the variance:
We see that the element m which minimizes (12) does not depend of σ, in particular we can assume , and wonder which elements minimizes , it becomes clear that only the points in the orbit of can minimize this variance. Then when ϵ is included in the set of fixed points, the estimation is always consistent for all σ. This is an alternative proof of the Theorem of consistency done by Kurtek et al. [1].
In the proof of Theorem 1, we have seen that the direction of the Fréchet mean of is given by the supremum of this quantity (7):
This Equation is a good illustration of the difficulty to compute the Fréchet mean in quotient space. Indeed, we have on one side the contribution of the noise and on the other side the contribution of the template , and we take the supremum of the sum of these two contributions over . Unfortunately the supremum of the sum of two terms is not equal to the sum of the supremum of each of these terms. Hence, it is difficult to separate these two contributions. However, we can intuit that when the noise is large, prevails over , and the use of the Cauchy-Schwarz inequality in Equations (8) and (9) proves it rigorously. We can conclude that, when the noise is large, the direction of the Fréchet mean in the quotient space depends more on the noise than on the template.
2.4. Template Estimation with the Max-Max Algorithm
2.4.1. Max-Max Algorithm Converges to a Local Minima of the Empirical Variance
Section 2.2 can be understood as follows: if we want to estimate the template by minimizing the Fréchet mean with quotient space, then there is a bias. This supposes that we are able to compute such a Fréchet mean. In practice, we cannot minimize the exact variance in quotient space, because we have only a finite sample and not the whole distribution. In this section we study the estimation of the empirical Fréchet mean with the max-max algorithm. We assume that the group is finite. In this case, the registration can always be found by an exhaustive search. Hence, the numeric experiments which we conduct in Section 2.5 lead to an empirical Karcher mean in a finite number of steps. In a compact group acting continuously, the registration also exists but is not necessarily computable without approximation.
If we have a sample: of independent and identically distributed copies of Y, then we define the empirical variance in the quotient space:
The empirical variance is an approximation of the variance. Indeed thanks to the law of large number we have for all . One element which minimizes globally (respectively locally) is called an empirical Fréchet mean (respectively an empirical Karcher mean). For and : where for all we define J an auxiliary function by:
The max-max Algorithm 1 iteratively minimizes the function J in the variable and in the variable (see Figure 5):
| Algorithm 1 Max-Max Algorithm. |
| Require: A starting point , a sample . . while Convergence is not reached do Minimizing : we get by registering with respect to . Minimizing : we get . . end while |
First, we note that this algorithm is sensitive to the the starting point. However we remark that for some , thus without loss of generality, we can start from for some . The empirical variance does not increase at each step of the algorithm since:
Proposition 1.
As the group is finite, the convergence is reached in a finite number of steps.
Proof of Proposition 1.
The sequence is non-increasing. Moreover the sequence takes value in a finite set which is: Therefore, the sequence is stationary. Let such that . Hence the empirical variance did not decrease between step n and step and we have:
as is the unique element which minimizes we conclude that . ☐
This proposition gives us a shutoff parameter in the max-max algorithm: we stop the algorithm as soon as . Let us call the final result of the max-max algorithm. It may seem logical that is at least a local minimum of the empirical variance. However this intuition may be wrong: let us give a toy counterexample, suppose that we observe , due to the transformation of the group it is possible that . We can start from in the max-max algorithm, as and 0 are already registered, the max-max algorithm does not transform . At step two, we still have , by induction the max-max algorithm stays at 0 even if 0 is not a Fréchet or Karcher mean of . Because 0 is equally distant from all the points in the orbit of , 0 is called a focal point of . The notion of focal point is important for the consistency of the Fréchet mean in manifold [22]. Fortunately, the situation where is not a Karcher mean is almost always avoided due to the following statement:
Proposition 2.
Let be the result of the max-max algorithm. If the registration of with respect to is unique, in other words, if is not a focal point of for all then is a local minimum of : is an empirical Karcher mean of .
Note that, if we call z the registration of y with respect to m, then the registration is unique if and only if for all . Once the max-max algorithm has reached convergence, it suffices to test this condition for obtained by the max-max algorithm and for all i. This condition is in fact generic and is always obtained in practice.
Proof of Proposition 2.
We call the unique element in G which register with respect to , for all , . By continuity of the norm we have for a close enough to m: for all (note that this argument requires a finite group). The registrations of with respect to m and to a are the same:
because has one unique local minimum . ☐
Remark 3.
We remark the max-max algorithm is in fact a gradient descent. The gradient descent is a general method to find the minimum of a differentiable function. Here we are interested in the minimum of the variance F: let and we define by induction the gradient descent of the variance , where and F the variance in the quotient space. In [7], the gradient of the variance in quotient space for finite group and for a regular point m was computed (m is regular as soon as implies ), this leads to:
where is the almost-surely unique element of the group which registers Y with respect to . Now if we have a set of data we can approximated the expectation which leads to the following approximated gradient descent:
now by taking we get . So the approximated gradient descent with is exactly the max-max algorithm. However, the max-max algorithm for finite group, is proved to be converging in a finite number of steps which is not the case for gradient descent in general.
2.5. Simulation on Synthetic Data
In this Section, we consider data in an Euclidean space equipped with its canonical dot product , and acts on by time translation on coordinates:
where indexes are taken modulo N. This space models the discretization of functions defined on with N points. This action is found in [19] and used for neuroelectric signals in [20]. The registration between two vectors can be made by an exhaustive research but it is faster with the fast Fourier transform [23].
2.5.1. Max-Max Algorithm with a Step Function as Template
We display an example of a template and template estimation with the max-max algorithm on Figure 6a. This experiment was already conducted in [19], but no explanation of the appearance of the bias was provided. We know from Section 2.4 that the max-max output is an empirical Karcher mean, and that this result can be obtained in a finite number of steps. Taking may seem extremely high, however the standard deviation of the noise at each point is not 10 but which is reasonable.
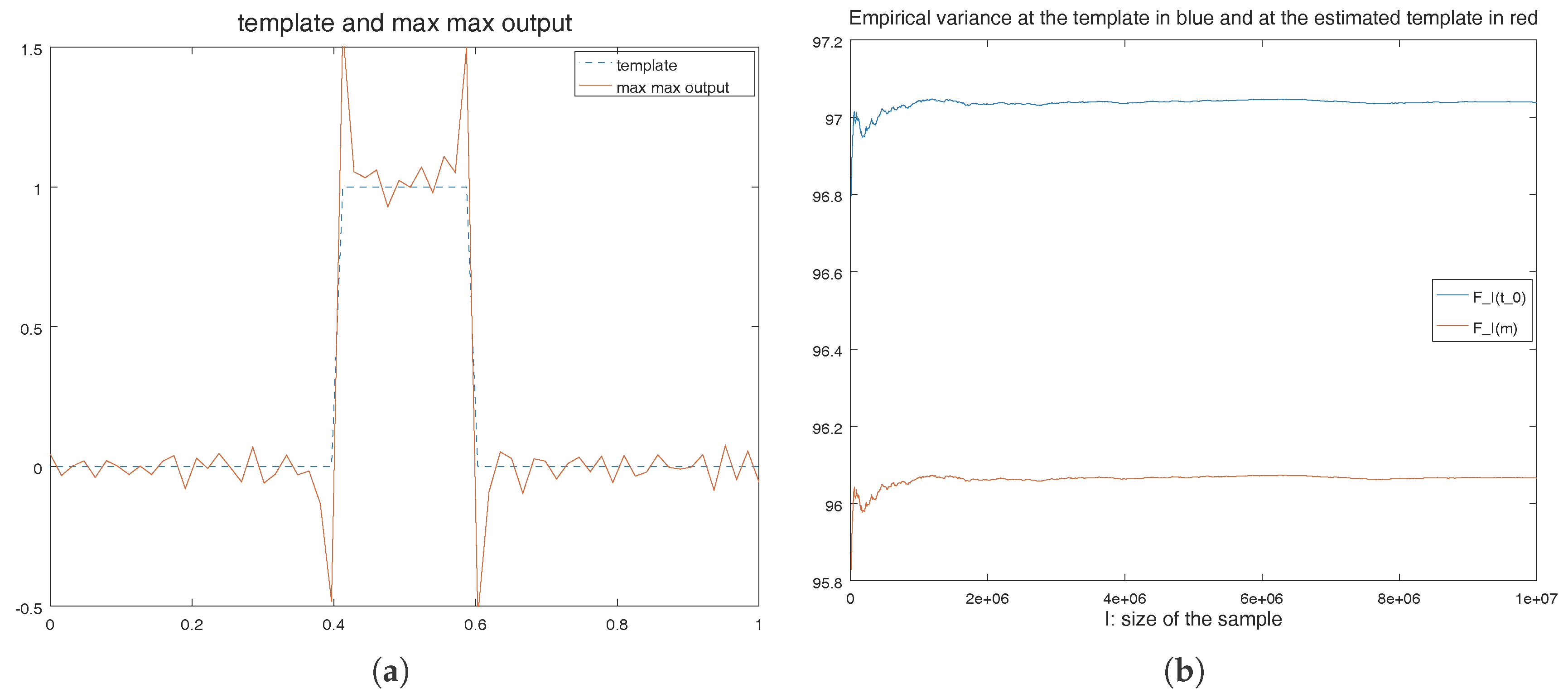
The sample size is , the algorithm stopped after 247 steps, and the estimated template (in red on the Figure 6a) is not a focal points of the orbits , then Proposition 2 applies. We call empirical bias (noted EB) the quotient distance between the true template and the point given by the max-max result. On this experiment we have . Of course, one could think that we estimate the template with an empirical bias due to a too small sample size which induces fluctuation. To reply to this objection, we keep in memory obtained with the max-max algorithm. If there was no inconsistency then we would have . We do not know the value of the variance F at these points, but thanks to the law of large number, we know that:
2.5.2. Max-Max Algorithm with a Continuous Template
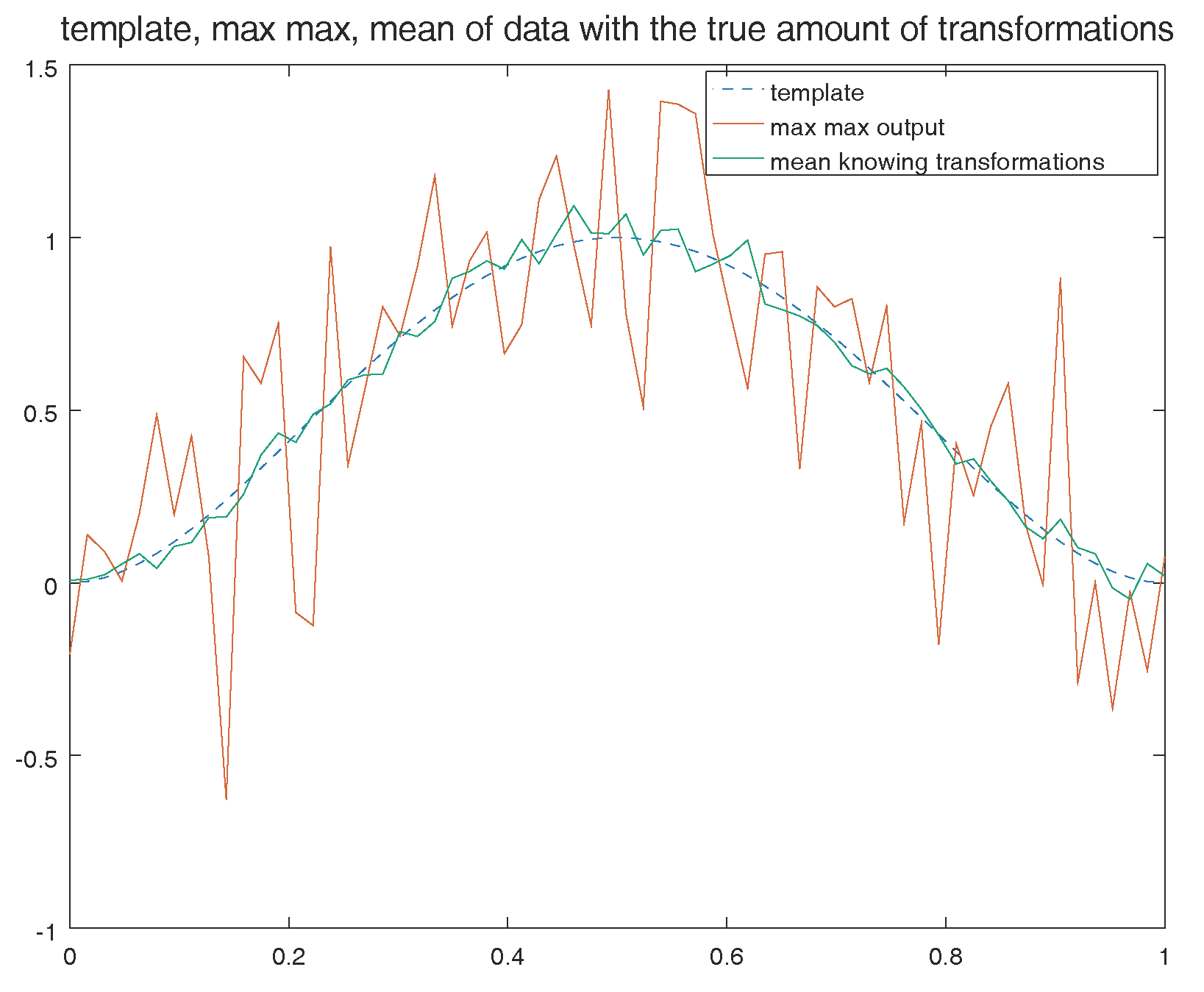
Figure 6a shows that the main source of the inconsistency was the discontinuity of the template. One may think that a continuous template would lead to a better behaviour. However, it is not the case as presented on Figure 7. Even with a large number of observations created from a continuous template we do not observe a convergence to the template. In the example of Figure 7, the empirical bias satisfies . In green we also display the mean of data knowing transformations, this produces a much better result, since that in this case we have .
2.5.3. Does the Max-Max Algorithm Give Us a Global Minimum or Only a Local Minimum of the Variance?
Proposition 2 tells us that the output of the max-max algorithm is a Karcher mean of the variance, but we do not know whether it is Fréchet mean of the variance. In other words, is the output a global minimum of the variance? In fact, has a lot of local minima which are not global. To illustrate this, we may use the max-max algorithm with different starting points and we observe different outputs (which are all local minima thanks to Proposition 2) with different empirical variance on Table 1.
3. Inconsistency in the Case of Non Invariant Distance under the Group Action
3.1. Notation and Hypothesis
In this Section, data still come from an Hilbert space M. However, we take a group of deformation G which acts in a non invariant way on M. Starting from a template we consider a random deformation in the group G namely a random variable which takes value in G and an standardized noise in M independent of . We suppose that our observable random variable is:
where is the noise level. We suppose that , and we define the pre-variance of Y in as the map defined by:
In this part we still study the inconsistency of template estimation by minimizing F.
We present two frameworks where we can ensure the presence of inconsistency: in Section 3.3 we suppose that the group G contains a non trivial group H which acts isometrically on M. However, some groups do not satisfy this hypothesis, that is why, in Section 3.4 we do not suppose that G contains a subgroup acting isometrically but we require that G acts linearly on M. In both sections we prove inconsistency as soon as the variance is large enough.
These hypothesis are not unacceptable as for example, deformations that are considered in computational anatomy may include rotations which form a subgroup H of the diffeomorphic deformations which acts isometrically. Concerning the second case, an important example is:
Example 4.
Let G be a subgroup of the group of diffeomorphisms on G acts linearly on with the map:
Note that this action is not isometric: indeed, has generally a different -norm than f, because a Jacobian determinant appears in the computation of the integral.
3.2. Where Did We Need an Isometric Action Previously?
Let M be an Hilbert space, and G a group acting on M. Can we define a distance in the quotient space defined as the set which contains all the orbits? When the action is invariant, the orbits are parallel in the sense where for all and for all . This implies that:
is a distance on Q. However, it is not necessarily the case when the action is no longer invariant. Let us take the following example:
Example 5.
We call the set of the diffeomorphisms of . We equip with its canonical Euclidean structure. We take , and (see Figure 8),
G acts on by . Then q and p are fixed points under this group action and the orbit of r is the horizontal line . On this example:
then the function is not symmetric. One could think define a distance by:
Unfortunately, in this case and then we do not have . In other words we do not have the triangular inequality.
Therefore when the action is no longer invariant, a priori one cannot define a distance in the quotient anymore. If Y is a random variable in M, cannot be interpreted as the variance of .
However is positive and is equal to zero if , then is a pre-distance in M. Then measures the discrepancy between the random point Y and the current point m. Even if the discrepancy measure is not symmetric or does not satisfy the triangular inequality, we can still define and call it the pre-variance of the projection of Y into , if . The elements which minimize this function are the element whose orbit are the closest of the random point Y. Hence, we wonder if the template can be estimated by minimizing this pre-variance. Note that, once again for all and . Then the pre-variance is well defined in the quotient space by .
It is not surprising to use a discrepancy measure which is not a distance, for instance the Kullback-Leibler divergence [24] is not symmetric although it is commonly used.
In the proof of inconsistency of Theorem 1, we used that the action was isometric in order to simplify the expansion of the variance in Equation (6):
with there was only one term which depends on g: and the two other terms could be pulled out of the infimum. When the action is no longer isometric we cannot do this trick anymore. To remedy this situation, in this article, we require that the orbit of the template is a bounded set.
In the following, we prove inconsistency even with non isometric action (but only when the noise level is large enough if the template is not a fixed point). The sketches of the different proofs are always the same: finding a point m such that , in order to do that it suffices to find an upper bound of and a lower bound of and to compare these two bounds.
3.3. Non Invariant Group Action, with a Subgroup Acting Isometrically
In this subsection G acts on M an Hilbert space. We assume that there exists a subgroup such that H acts isometrically on M. As H is included in G, we deduce a useful link between the variance of Y projected in and the pre-variance of Y projected in :
The orbit of a point m under the group action G is , whereas the orbit of the point m under the group action H is . Moreover, we call the variance of in the quotient space , and F the variance of in the quotient space .
3.3.1. Inconsistency when the Template Is a Fixed Point
We begin by assuming that the template is a fixed point under the action of G:
Proposition 3.
Suppose that is a fixed point under the group action G. Let ϵ be a standardized noise which support is not included in the fixed points under the group action of H, and . Then is not a minimum of the pre-variance F.
Proof.
We have:
- Thanks to Corollary 1 of Section 2.2 we know that is not the Fréchet mean of the projection of Y into : we can find such that:Note that in order to apply Corollary 1, we do not need that is included in H, because is a fixed point.
- Because we take the infimum over more elements we have:
- As is a fixed point under the action of G and under the action of H:
3.3.2. Inconsistency in the General Case for the Template
The following Proposition 4 tells us that when is large enough then there is an inconsistency.
Proposition 4.
We suppose that the template is not a fixed point and that its orbit under the group G is bounded. We consider and , note that and we have:
We note:
We suppose that . If σ is bigger than a critical noise level noted defined as:
Then we have inconsistency.
Note that in Section 2.2 we have proved inconsistency in the isometric case as soon as , where , then we find in this theorem an analogical sufficient condition on where is a corrective term due to the non invariant action.
We have shown in [7] that if the orbit of the template is a manifold, then as soon as the support of is not included in (the normal space of the orbit of the template at the point ). If is not a manifold, we have also seen in [7] that as soon as is an accumulation point of and the support of contains a ball . Hence, is a rather generic condition. Condition (18) can be reformulated as follows: as soon as the signal to noise ratio is sufficiently small:
then there is inconsistency.
We remark the presence of the constants and in Proposition 4. This kind of constants were already here in the isometric case under the form , due to the polarization identity (2), we can state that it measures how much the template looks like to the noise after registration, but only in the isometric case. However we can intuit that this constant plays a analogical role in the non isometric case.
Example 6.
Let G acting on M, we suppose that G contains the orthogonal group of M. Assume that G can modifying the norm of the template by multiplying its norm by at most 2. Then we can set up and . By aligning ϵ and we have , and then when the signal to noise ratio is smaller that then there is inconsistency. By Cauchy-Schwarz inequality we have , thus the signal to noise ratio has to be rather small in order to fulfill this condition.
3.3.3. Proof of Proposition 4
We define the following values:
Note that and are registration scores which definitions are the same than the registration score used in the proof of Theorem 1 in Section 2 (only the normalization by is different). The proof of Proposition 4 is based on the following Lemma:
Lemma 1.
If:
then is not a minimizer of the pre-variance of in .
How condition (20) can be understood? In order to answer to that question, let us imagine that acts isometrically, then a can be set up to 1, and the condition (20) becomes and the conditions of Theorem 4.2 of [7] aimed to ensure that . Now let us return to the non invariant case: if H is strictly included in G such that a is closed enough to 1 and closed enough to , then on can think that condition (20) still holds. However, the closed enough seems hard to be quantified.
Proof of Lemma 1.
The proof is based on the following points:
- ,
- .
With items 1 and 2 we get that . items 1 is just based on the fact that in the map F, we take the infimum on a larger set than on . We now prove item 2, in order to do that we expand the two quantities, firstly:
We use the fact that H acts isometrically between Equations (21) and (22) and the fact that because is true for any A subset of if . Secondly:
Then:
thanks to hypothesis (20). ☐
Proof of Proposition 4.
In order to prove Proposition 4, all we have to do is proving and proving that Condition (20) is fulfilled when . Firstly, thanks to Cauchy-Schwarz inequality, we have:
Note that as we get , this proves (19). We also have:
Then we can find a lower bound of :
For where is the biggest solution of the quadratic Equation , we get and template estimation is inconsistent thanks to Lemma 1. The critical is exactly the one given by Proposition 4. ☐
3.4. Linear Action
The result of the previous part has a drawback, it requires that the group of deformations contains a non trivial subgroup which acts isometrically. We know remove this hypothesis, but we require that the group acts linearly on data.
3.4.1. Inconsistency
In this Subsection we suppose that the group G acts linearly on M. Once again, we can give a criteria on the noise level which leads to inconsistency:
Proposition 5.
We suppose that the orbit of the template is bounded with:
We suppose that . In other words, the deformation of the template can multiply the norm of the template by less than . We also suppose that:
There is inconsistency as soon as
Example 7.
For instance if , then there is inconsistency if .
Once again we find a condition which is similar to the isometric case, but due to the non invariant action we have here a corrective term which depends on A and a. Note that as G does not act isometrically, results in [7] do not apply in order to fulfill Condition (23). However it is easy to fulfill this Condition thanks to the following Proposition:
Proposition 6.
If is not a fixed point, and if the support of ϵ contains a ball for then
Remark 4.
It is possible to remove the condition in Proposition 5. Indeed Let be such that:
The template can be replaced by since is equal to and applying Proposition 5 to the new template . We get that does not minimize the variance F with (because the new template is . Since does not minimize F, the original template does not minimize the pre-variance F neither, since .
This changes the critical since we apply Proposition 5 to instead of itself.
3.4.2. Proofs of Proposition 5 and Proposition 6
As in Section 3.3 we first prove a Lemma:
Lemma 2.
We define:
Suppose that and that:
Then is not a minimum of F.
Proof of Lemma 2.
Since
then by linearity of the action we get:
We remind that:
We get:
Note that we use the fact that the action is linear in Equation (27). We obtain that is not the minimum of the F:
☐
Proof of Proposition 5.
By solving the following quadratic inequality we remark that:
Besides, as in Section 3.3.2 we can take a lower bound of by decomposing and applying Cauchy-Schwarz inequality , we get:
Thanks to Condition (28) and the fact that we get:
Then and Condition (24) is fulfilled. Thus, there is inconsistency, according to Lemma 2. ☐
Proof of Proposition 6.
First we notice that:
In order to have , first we show that it exists and such that
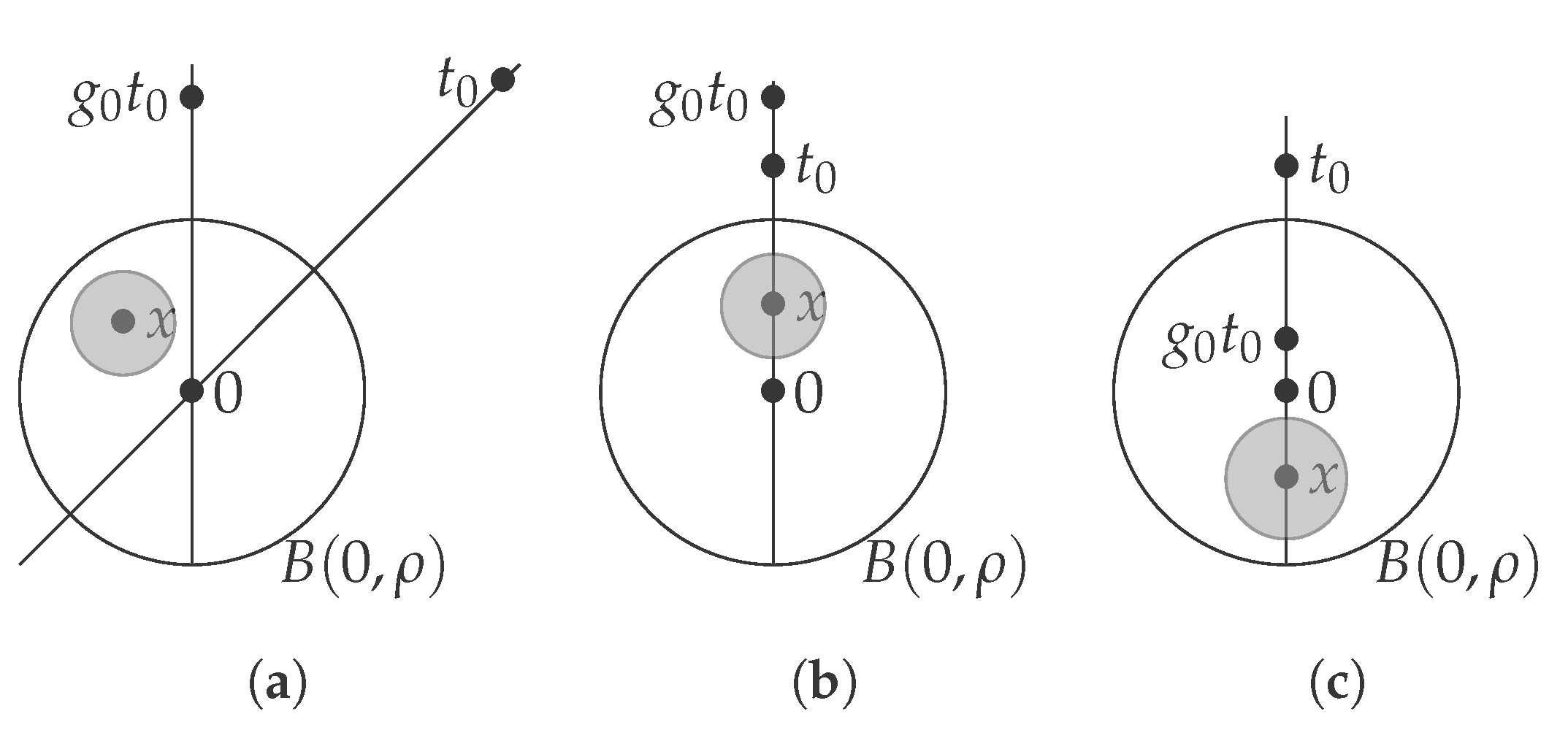
Let such that . There are three cases to be distinguished (see Figure 9):
- The vectors and are linearly independent. In this case , then we can find and . Then and , without loss of generality we can assume that (replacing x by if necessary). We also can assume that (replacing x by if necessary. Then we have and:
- If with , we take and we have:
- If with we take and we have:
In all these cases we can find x such that By continuity it exists such that for all y on this ball we have . Then the event has non zero probability, since x is in the support of we have . Thus Inequality in (29) will be strict. This proves that . ☐
3.5. Example of a Template Estimation Which is Consistent
In order to underline the importance of the hypotheses, we give an example where the method is consistent:
Example 8.
Let M be an Hilbert space and V a closed sub-linear space of M. Then acts on M by (see Figure 10):
This action is not isometric, indeed is not linear (except if ). However this action is invariant, let us consider the orthogonal space of V. The variance in the quotient space is:
where the orthogonal projection on . Then it is clear that minimizes F. In fact, is just a congruent section of the quotient (see Section 2.1). Here, once again, we see the role played by the the congruent section (when it exists) in order to study the consistency.
Hence, is there a contradiction with Proposition 4 or Proposition 5 which prove inconsistency as soon as the noise level is large enough? In Proposition 4, we require that there is a subgroup acting isometrically, in this example the only element which acts linearly is the identity element , then is the only possibility, however the support of the noise should not be included in the set of fixed point under the group action of H. Here, all points are fixed under H, hence it is not possible to fulfill this condition. Example 8 is not a contradiction with Proposition 4, it is also not a contradiction with Proposition 5 since it does not act linearly on data.
3.6. Inconsistency with Non Invariant Action and Regularization
In practice people add a regularization term in the function they minimize in LDDMM [11,14], or in Demons [25] etc. Because, if one considers two points, one does not want necessarily to fit one with the other. Indeed, even if one deformation matches exactly these two points, it may be an unrealistic deformation. So far, we did not study the use of such a term in the inconsistency.
3.6.1. Case of Deformations Closed to the Identity Element of G
If we suppose that the deformations of the template is closed to identity, it is useless to take the infimum over G because G contains big deformations. Perhaps one of these big deformations can reaches the infimum in F, but this element is not the one which deformed the template in the generative model. Then such big deformations should not be taken into account. That is why, if we suppose that G can be equipped with a distance , then we can assume that there exists such that the deformation belongs almost surely to
Instead of defining as , one can define , and the previous proofs will still be true, when replacing for instance by etc. Likewise we need to replace the hypothesis “the support of is not included in the set of fixed points” by ”the support of in not included is the set of fixed points under the action restricted to ”.
Note that restraining ourselves to is equivalent to add a following regularization on the function F:
Moreover considering only the elements in will automatically satisfy the condition in Proposition 5 as long as the group G acts continuously on the template, if r is small enough.
3.6.2. Inconsistency in the Case of a Group Acting Linearly with a Bounded Regularization
In this Section we suppose that the group G acts linearly. We also suppose that . The regularization term is a bounded map . With this framework, we still able to prove that there is inconsistency as soon as the noise level is large enough:
Proposition 7.
Let G be a group acting linearly on M. We suppose that the orbit of the template is bounded with , the generative model is still . We define the pre-variance as:
Then as soon as the noise level is large enough, i.e.,:
Then is not a minimizser of F.
The proof is exactly the same as the Proof of Proposition 5, we take 0 as a lower bound of the the regularization term in the lower bound of , and we take as a upper bound of the regularization term in the upper bound of . We solve a similar quadratic equation in order to find the critical .
4. Conclusions and Discussion
We provided an asymptotic behavior of the consistency bias when the noise level tends to infinity in the case of isometric action. As a consequence, the inconsistency can not be neglected when is large. When the action is no longer isometric, inconsistency has been also shown when the noise level is large.
However, we have not answered this question: can the inconsistency be neglected? When the noise level is small enough, then the consistency bias is small [6,7], hence it can be neglected. Note that the quotient space is not a manifold, this prevents us to use a priori the Central Limit theorem for manifold proved in [22]. However, if the Central Limit theorem could be applied to quotient space, the fluctuations induces an error which would be approximately equal to and if , then the inconsistency could be neglected because it is small compared to fluctuation. One way to avoid the inconsistency is to use another framework, for a instance a Bayesian paradigm [26].
In the numerical experiments we presented, we have seen that the estimated template is more crispy that the true template. The intuition is that the estimated template in computational anatomy with a group of diffeomorphisms is also more detailed. However, the true template is almost always unknown. It is then possible that one think that the computation of the template succeeded to capture small details of the template while it is just an artifact due to the inconsistency. Moreover in order to tackle this question, one needs to have a good modeliation of the noise, for instance in [1], the observations are curves, what is a relevant noise in the space of curves?
In this article, we have considered actions which do not let the distance invariant. Although we have only shown the inconsistency as soon as the noise level is large enough, the inequality used where not optimal at all, surely future works could improve this work and prove that inconsistency appears for small noise level. Moreover a quantification of the inconsistency should be established.
Author Contributions
Loïc Devilliers elaborated the main results and wrote the article; Stéphanie Allassonnière, Alain Trouvé and Xavier Pennec have co-supervised this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kurtek, S.A.; Srivastava, A.; Wu, W. Signal Estimation Under Random Time-Warpings and Nonlinear Signal Alignment. In Advances in Neural Information Processing Systems 24; Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2011; pp. 675–683. [Google Scholar]
- Guimond, A.; Meunier, J.; Thirion, J.P. Average Brain Models: A Convergence Study. Comput. Vis. Image Underst. 2000, 77, 192–210. [Google Scholar] [CrossRef]
- Joshi, S.; Davis, B.; Jomier, M.; Gerig, G. Unbiased diffeomorphic atlas construction for computational anatomy. Neuroimage 2004, 23, S151–S160. [Google Scholar] [CrossRef] [PubMed]
- Cootes, T.F.; Marsland, S.; Twining, C.J.; Smith, K.; Taylor, C.J. Groupwise diffeomorphic non-rigid registration for automatic model building. In Computer Vision—ECCV 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 316–327. [Google Scholar]
- Bigot, J.; Charlier, B. On the consistency of Fréchet means in deformable models for curve and image analysis. Electron. J. Stat. 2011, 5, 1054–1089. [Google Scholar] [CrossRef]
- Miolane, N.; Holmes, S.; Pennec, X. Template shape estimation: Correcting an asymptotic bias. SIAM J. Imaging Sci. 2017, 10, 808–844. [Google Scholar] [CrossRef]
- Devilliers, L.; Allassonnière, S.; Trouvé, A.; Pennec, X. Template estimation in computational anatomy: Fréchet means in top and quotient spaces are not consistent. SIAM J. Imaging Sci. 2017, in press. [Google Scholar]
- Panaretos, V.M.; Zemel, Y. Amplitude and phase variation of point processes. Ann. Stat. 2016, 44, 771–812. [Google Scholar] [CrossRef]
- Devilliers, L.; Pennec, X.; Allassonnière, S. Inconsistency of Template Estimation with the Fréchet Mean in Quotient Space. In Information Processing in Medical Imaging, Proceedings of the 25th International Conference (IPMI 2017), Boone, NC, USA, 25–30 June 2017; Niethammer, M., Styner, M., Aylward, S., Zhu, H., Oguz, I., Yap, P.T., Shen, D., Eds.; Springer: Cham, Switzerland, 2017; pp. 16–27. [Google Scholar]
- Thompson, D.W. On Growth and Form; Cambridge University Press: Cambridge, UK, 1942. [Google Scholar]
- Durrleman, S.; Prastawa, M.; Charon, N.; Korenberg, J.R.; Joshi, S.; Gerig, G.; Trouvé, A. Morphometry of anatomical shape complexes with dense deformations and sparse parameters. NeuroImage 2014, 101, 35–49. [Google Scholar] [CrossRef] [PubMed]
- Glasbey, C.; Mardia, K. A penalized likelihood approach to image warping. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 465–492. [Google Scholar] [CrossRef]
- Charlier, B. Necessary and sufficient condition for the existence of a Fréchet mean on the circle. ESAIM Probab. Stat. 2013, 17, 635–649. [Google Scholar] [CrossRef]
- Beg, M.F.; Miller, M.I.; Trouvé, A.; Younes, L. Computing large deformation metric mappings via geodesic flows of diffeomorphisms. Int. J. Comput. Vis. 2005, 61, 139–157. [Google Scholar] [CrossRef]
- Huckemann, S. Inference on 3d procrustes means: Tree bole growth, rank deficient diffusion tensors and perturbation models. Scand. J. Stat. 2011, 38, 424–446. [Google Scholar] [CrossRef]
- Rohlf, F.J. Bias and error in estimates of mean shape in geometric morphometrics. J. Hum. Evol. 2003, 44, 665–683. [Google Scholar] [CrossRef]
- Goodall, C. Procrustes methods in the statistical analysis of shape. J. R. Stat. Soc. Ser. B Methodol. 1991, 53, 285–339. [Google Scholar]
- Ziezold, H. On expected figures and a strong law of large numbers for random elements in quasi-metric spaces. In Transactions of the Seventh Prague Conference on Information Theory, Statistical Decision Functions, Random Processes and of the 1974 European Meeting of Statisticians; Springer: Dordrecht, The Netherlands, 1977; pp. 591–602. [Google Scholar]
- Allassonnière, S.; Amit, Y.; Trouvé, A. Towards a coherent statistical framework for dense deformable template estimation. J. R. Stat. Soc. Ser. B Stat. Methodol. 2007, 69, 3–29. [Google Scholar] [CrossRef]
- Hitziger, S.; Clerc, M.; Gramfort, A.; Saillet, S.; Bénar, C.; Papadopoulo, T. Jitter-adaptive dictionary learning-application to multi-trial neuroelectric signals. arXiv, 2013; arXiv:1301.3611. [Google Scholar]
- Kurtek, S.; Klassen, E.; Ding, Z.; Avison, M.J.; Srivastava, A. Parameterization-invariant shape statistics and probabilistic classification of anatomical surfaces. In Proceedings of the 22nd International Conference on Information Processing in Medical Imaging, Monastery Irsee, Germany, 3–8 July 2011; pp. 147–158. [Google Scholar]
- Bhattacharya, A.; Bhattacharya, R. Statistics on Riemannian manifolds: Asymptotic distribution and curvature. Proc. Am. Math. Soc. 2008, 136, 2959–2967. [Google Scholar] [CrossRef]
- Cooley, J.W.; Tukey, J.W. An algorithm for the machine calculation of complex Fourier series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Lombaert, H.; Grady, L.; Pennec, X.; Ayache, N.; Cheriet, F. Spectral Log-Demons: Diffeomorphic Image Registration with Very Large Deformations. Int. J. Comput. Vis. 2013, 107, 254–271. [Google Scholar] [CrossRef]
- Cheng, W.; Dryden, I.L.; Huang, X. Bayesian registration of functions and curves. Bayesian Anal. 2016, 11, 447–475. [Google Scholar] [CrossRef]
Figure 1.
Three functions defined on the interval . The blue one () is a step function, the red one () is a translated version of the blue one when noise has been added, and the green one () is the null function.
Figure 1.
Three functions defined on the interval . The blue one () is a step function, the red one () is a translated version of the blue one when noise has been added, and the green one () is the null function.

Figure 2.
Due to the invariant action, the orbits are parallel. Here the orbits are circles centred at 0. This is the case when the group G is the group of rotations.
Figure 2.
Due to the invariant action, the orbits are parallel. Here the orbits are circles centred at 0. This is the case when the group G is the group of rotations.

Figure 3.
Representation of the three functions , and with . the functions and are registered with respect to . However and are not registered with each other, since it is more profitable to shift in order to align the highest parts of and .
Figure 3.
Representation of the three functions , and with . the functions and are registered with respect to . However and are not registered with each other, since it is more profitable to shift in order to align the highest parts of and .

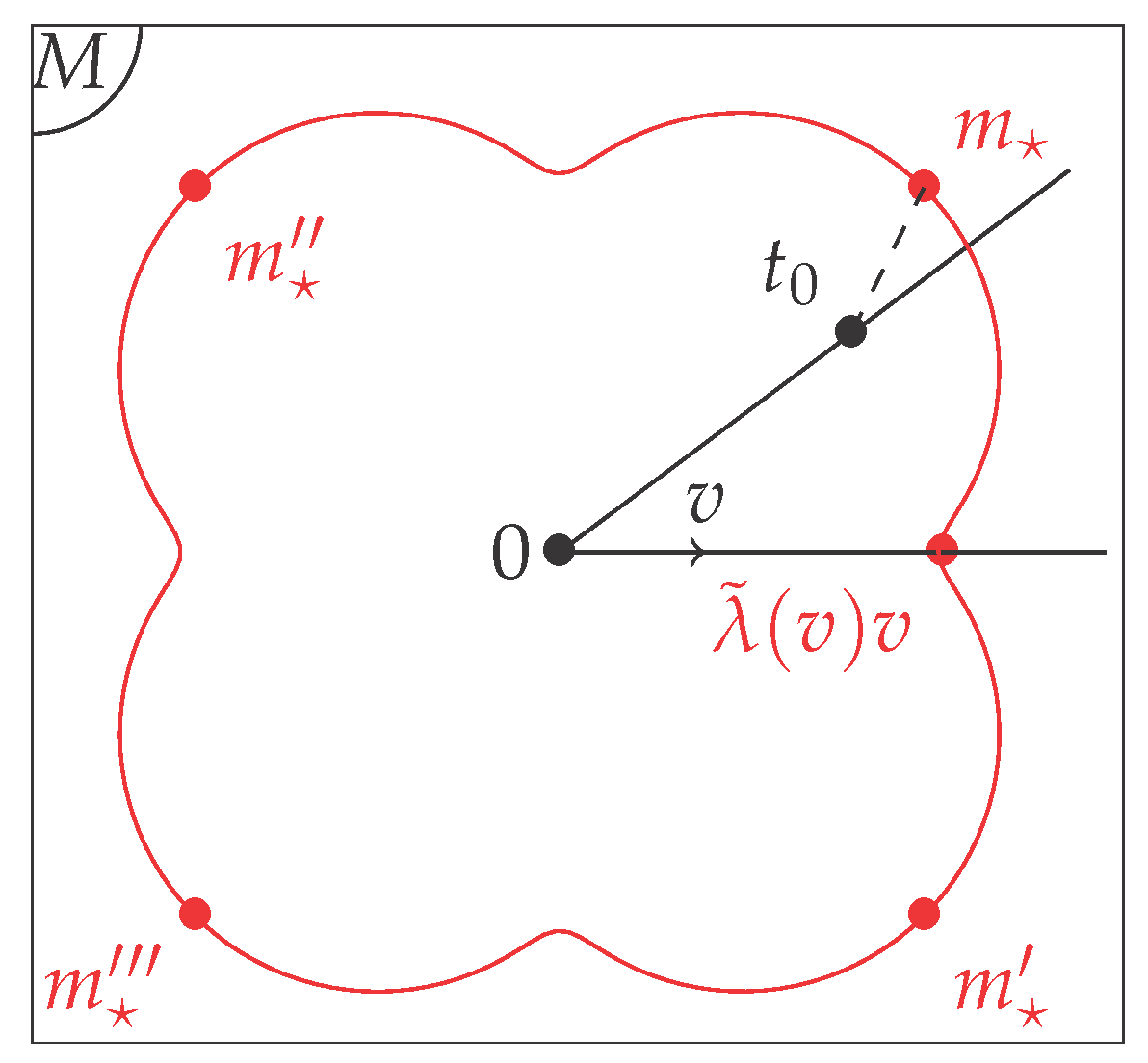
Figure 4.
We minimize the variance on each half-line where . The element which minimizes the variance on such a half-line is , where . We get a surface in M by (which is a curve in this figure since we draw it in dimension 2). The Proof of Theorem 1 states that if is a Fréchet mean then is an extreme point of this surface. On this picture there are four extreme points which are in the same orbit: we took here the simple example of the group of rotations of 0, 90, 180 and 270 degrees.
Figure 4.
We minimize the variance on each half-line where . The element which minimizes the variance on such a half-line is , where . We get a surface in M by (which is a curve in this figure since we draw it in dimension 2). The Proof of Theorem 1 states that if is a Fréchet mean then is an extreme point of this surface. On this picture there are four extreme points which are in the same orbit: we took here the simple example of the group of rotations of 0, 90, 180 and 270 degrees.

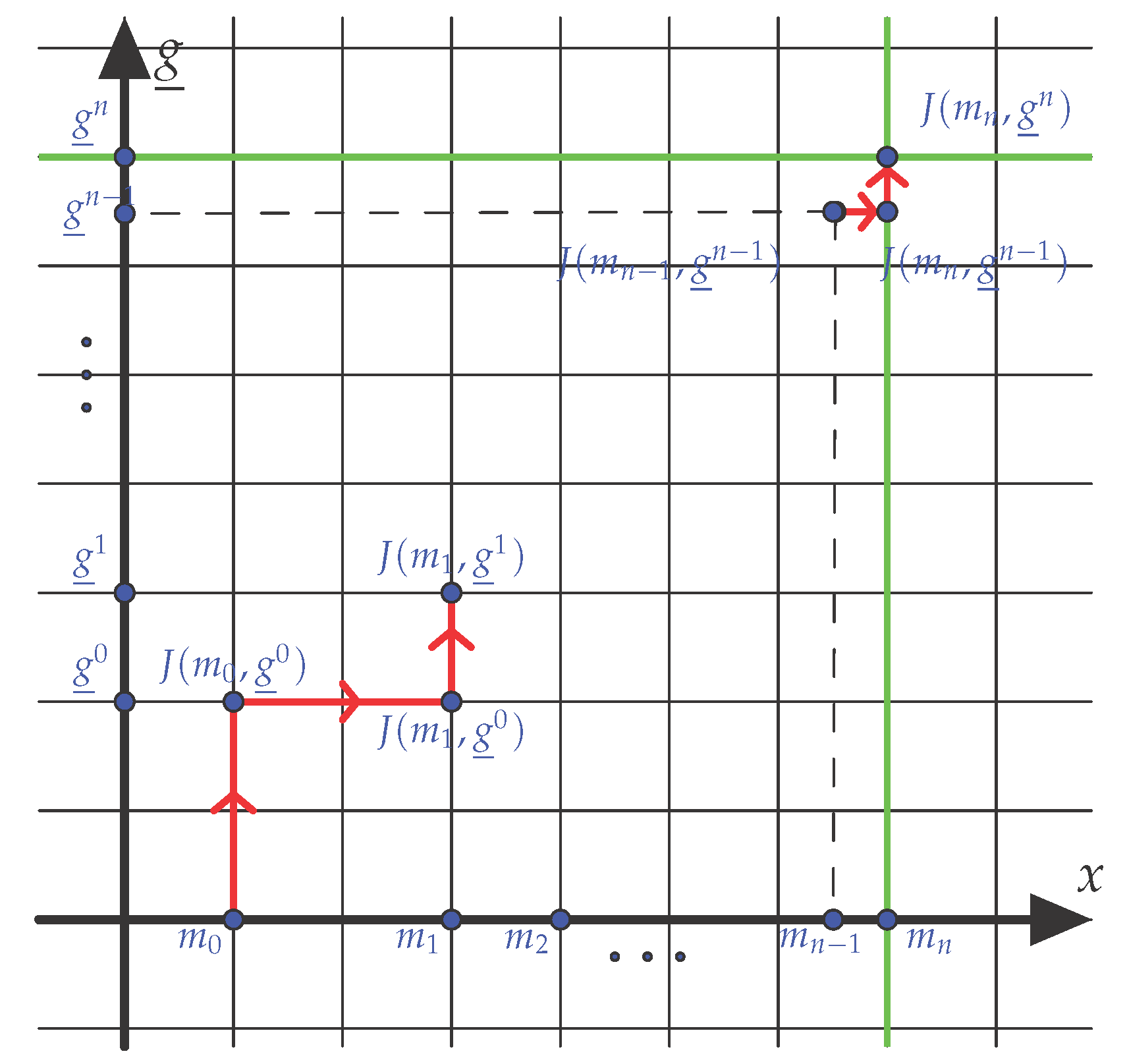
Figure 5.
Iterative minimization of the function J on the two axis, the horizontal axis represents the variable in the space M, the vertical axis represents the set of all the possible registrations . Once the convergence is reached, the point is the minimum of the function J on the two axis in green. Is this point the minimum of J on its whole domain? There are two pitfalls: firstly this point could be a saddle point, it can be avoided with Proposition 2, secondly this point could be a local (but not global) minimum, this is discussed in Section 2.5.3.
Figure 5.
Iterative minimization of the function J on the two axis, the horizontal axis represents the variable in the space M, the vertical axis represents the set of all the possible registrations . Once the convergence is reached, the point is the minimum of the function J on the two axis in green. Is this point the minimum of J on its whole domain? There are two pitfalls: firstly this point could be a saddle point, it can be avoided with Proposition 2, secondly this point could be a local (but not global) minimum, this is discussed in Section 2.5.3.

Figure 6.
Template and template estimation on Figure 6a. Empirical variance at the template and template estimation with the max-max algorithm as a function of the size of the sample on Figure 6b. (a) Example of a template (a step function) and the estimated template with a sample size in , is Gaussian noise and . At the discontinuity points of the template, we observe a Gibbs-like phenomena; (b) Variation of (in blue) and of (in red) as a function of I the size of the sample. Since convergence is already reached, , which is the limit of red curve, is below : is the limit of the blue curve. Due to the inconsistency, is an example of point such that .
Figure 6.
Template and template estimation on Figure 6a. Empirical variance at the template and template estimation with the max-max algorithm as a function of the size of the sample on Figure 6b. (a) Example of a template (a step function) and the estimated template with a sample size in , is Gaussian noise and . At the discontinuity points of the template, we observe a Gibbs-like phenomena; (b) Variation of (in blue) and of (in red) as a function of I the size of the sample. Since convergence is already reached, , which is the limit of red curve, is below : is the limit of the blue curve. Due to the inconsistency, is an example of point such that .

Figure 7.
Example of an other template (here a discretization of a continuous function) and template estimation with a sample size in , is Gaussian noise and . Even with a continuous function the inconsistency appears.
Figure 7.
Example of an other template (here a discretization of a continuous function) and template estimation with a sample size in , is Gaussian noise and . Even with a continuous function the inconsistency appears.

Figure 8.
Example of three orbits, when does not satisfy the inequality triangular.

Figure 9.
Representation of the three cases, on each we can find an x in the support of the noise such as and by continuity of the dot product with is an event with a non zero probability, (for instance the ball in gray). This is enough in order to show that . (a) Case 1: and are linearly independent; (b) Case 2: is proportional to with a factor ; (c) Case 3: is proportional to with a factor .
Figure 9.
Representation of the three cases, on each we can find an x in the support of the noise such as and by continuity of the dot product with is an event with a non zero probability, (for instance the ball in gray). This is enough in order to show that . (a) Case 1: and are linearly independent; (b) Case 2: is proportional to with a factor ; (c) Case 3: is proportional to with a factor .

Figure 10.
In the case of affine translation by vectors of V, the orbits are affine subspace parallel to V. The distance between two orbits and is given by the distance between the orthogonal projection of x and y in . This is an example where template estimation is consistent.
Figure 10.
In the case of affine translation by vectors of V, the orbits are affine subspace parallel to V. The distance between two orbits and is given by the distance between the orthogonal projection of x and y in . This is an example where template estimation is consistent.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
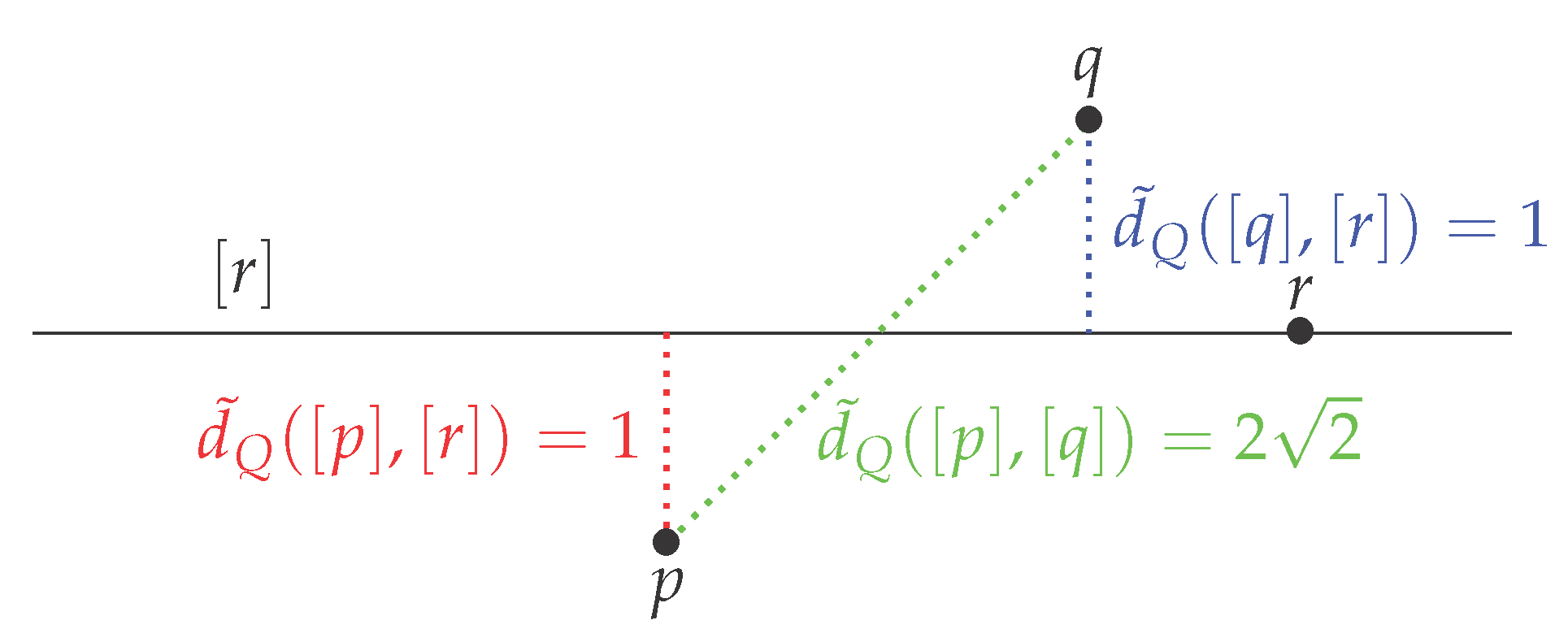{kind=link}
{kind=link}
{kind=link}
Table 1.
Empirical variances at 5 different outputs of the max-max algorithm coming from the same sample of size , but with different starting points. We use and the action of time translation in . Conclusion: on these five points, only is an eventual global minima.
Table 1.
Empirical variances at 5 different outputs of the max-max algorithm coming from the same sample of size , but with different starting points. We use and the action of time translation in . Conclusion: on these five points, only is an eventual global minima.
| Points | Template | |||||
|---|---|---|---|---|---|---|
| Empirical variance at these points | 96.714 | 95.684 | 95.681 | 95.676 | 95.677 | 95.682 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Devilliers, L.; Allassonnière, S.; Trouvé, A.; Pennec, X. Inconsistency of Template Estimation by Minimizing of the Variance/Pre-Variance in the Quotient Space. Entropy 2017, 19, 288. https://doi.org/10.3390/e19060288
AMA Style
Devilliers L, Allassonnière S, Trouvé A, Pennec X. Inconsistency of Template Estimation by Minimizing of the Variance/Pre-Variance in the Quotient Space. Entropy. 2017; 19(6):288. https://doi.org/10.3390/e19060288
Chicago/Turabian StyleDevilliers, Loïc, Stéphanie Allassonnière, Alain Trouvé, and Xavier Pennec. 2017. "Inconsistency of Template Estimation by Minimizing of the Variance/Pre-Variance in the Quotient Space" Entropy 19, no. 6: 288. https://doi.org/10.3390/e19060288
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.