A New Efficient Expression for the Conditional Expectation of the Blind Adaptive Deconvolution Problem Valid for the Entire Range ofSignal-to-Noise Ratio

Department of Electrical and Electronic Engineering, Ariel University, Ariel 40700, Israel
Entropy 2019, 21(1), 72; https://doi.org/10.3390/e21010072
Submission received: 10 December 2018
/
Revised: 9 January 2019
/
Accepted: 14 January 2019
/
Published: 15 January 2019
(This article belongs to the Special Issue Information Theory Applications in Signal Processing)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In the literature, we can find several blind adaptive deconvolution algorithms based on closed-form approximated expressions for the conditional expectation (the expectation of the source input given the equalized or deconvolutional output), involving the maximum entropy density approximation technique. The main drawback of these algorithms is the heavy computational burden involved in calculating the expression for the conditional expectation. In addition, none of these techniques are applicable for signal-to-noise ratios lower than 7 dB. In this paper, I propose a new closed-form approximated expression for the conditional expectation based on a previously obtained expression where the equalized output probability density function is calculated via the approximated input probability density function which itself is approximated with the maximum entropy density approximation technique. This newly proposed expression has a reduced computational burden compared with the previously obtained expressions for the conditional expectation based on the maximum entropy approximation technique. The simulation results indicate that the newly proposed algorithm with the newly proposed Lagrange multipliers is suitable for signal-to-noise ratio values down to 0 dB and has an improved equalization performance from the residual inter-symbol-interference point of view compared to the previously obtained algorithms based on the conditional expectation obtained via the maximum entropy technique.
1. Introduction
In this paper, the blind adaptive deconvolution problem is addressed, which arises in many applications, such as seismology, underwater acoustic, image restoration and digital communication [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35]. In digital communication applications, the problem is often called blind adaptive equalization. Non-blind adaptive equalizers, unlike blind adaptive equalizers, require training symbols to generate the error that is fed into the adaptive mechanism which updates the equalizer’s taps. Therefore, blind adaptive equalizers have some important advantages compared with the non-blind version: (1) Simplified protocols in point-to-point communications, avoiding the retransmission of training symbols after abrupt changes of the channel. (2) Higher bandwidth efficiency in broadcast networks. (3) Reduced interoperability problems derived from the use of different training symbols. It is well known that inter-symbol interference (ISI) is a limiting factor in many communication environments, where it causes an irreducible degradation of the bit error rate thus imposing an upper limit on the data symbol rate [36]. In order to overcome the ISI problem, an equalizer is implemented in those systems [34,35,36,37,38,39,40,41]. In this work, the T-spaced blind adaptive equalizer is considered for the single-input-single-output (SISO) case where the sampling rate is equal to the symbol rate (thus referred to as T-spaced where T denotes the baud, or symbol, duration). Please note that a fractionally-spaced equalizer (FSE) where the sampling rate is higher than the symbol rate can be modeled with a single-input-multiple-output (SIMO) system. In addition, a SIMO system can be modeled with a parallel combination of T-spaced blind adaptive equalizers. Thus, improving the equalization performance of a T-spaced blind adaptive equalizer for the SISO case may also lead to equalization performance improvement for the SIMO case. As already mentioned above, blind adaptive equalizers do not use any training symbols to generate the error that is fed into the adaptive mechanism which updates the equalizer’s taps. Instead of those training symbols, an estimate of the desired response is obtained via the use of a nonlinear transformation to sequences involved in the adaptation process. Now, very often, blind adaptive equalization algorithms are classified according to the location of their nonlinearity in the algorithm chain [42]. According to Reference [42], there are three different types: (1) polyspectral algorithms, (2) Bussgang-type algorithms, (3) probabilistic algorithms. In the first method, the nonlinearity is located at the output of the channel, right before the equalizer. Thus, the nonlinearity actually estimates the channel. This estimation is fed into the adaptive mechanism which updates the equalizer’s taps. In the second type, the nonlinearity is situated at the output of the equalizer. Here, the nonlinearity can just be the estimation of the source signal via the the use of the conditional expectation (the expectation of the source input given the equalized or deconvolutional output), or the nonlinearity can be a predefined cost function that holds some information of the ISI. Thus, minimizing this predefined cost function with respect to the equalizer’s taps may lower the residual ISI and help in the symbol recovery process. Since Bussgang-type algorithms often have shorter convergence times than polyspectral methods, which need larger amounts of data for an equivalent estimation variance, they are more popular [42]. In the third class of algorithms, directly locating the nonlinearity is more problematic compared to the first two groups since the nonlinearity is combined with the data detection process. While these algorithms can extract considerable information from relatively little data, this is often accomplished at a huge computational cost [42]. In the following, the Bussgang-type blind equalization algorithms are considered, where the conditional expectation (the expectation of the source input given the equalized or deconvolutional output) is derived for estimating the desired response. In the literature, we can find several approximated expressions for the conditional expectation related to the blind adaptive deconvolutional problem [20,43,44,45,46,47,48,49]. However, References [43,44,45,46] are valid only for a uniformly distributed source input and References [20,47,48] were designed only for the noiseless case. Recently [49], a new blind adaptive equalization method was proposed based on Reference [47] that is applicable for signal-to-noise ratio (SNR) values down to 7 dB. However, the computational burden of the method in Reference [49] is relative high. The closed-form approximated expression proposed in Reference [49] for the conditional expectation with Lagrange multipliers up to order four (thus applicable for the 16QAM input case) is composed of a polynomial function of the equalized output of order twenty one. Please note that the proposed expression for the conditional expectation with Lagrange multipliers up to order four in Reference [47] is a polynomial function of the equalized output of order thirteen while the proposed expression for the conditional expectation with Lagrange multipliers up to order four in Reference [20] is a fraction where the numerator and the denominator are a polynomial function of the equalized output of order thirteen and twelve, respectively.
In this paper, I propose a new closed-form approximated expression for the conditional expectation based on Reference [20] with Lagrange multipliers up to order four. This new proposed expression has a reduced computational burden compared with the previously obtained expressions for the conditional expectation proposed in Reference [20,47,49]. The new proposed expression for the conditional expectation is composed of a fraction where the numerator and the denominator are a polynomial function of the equalized output of order seven and six, respectively. Simulation results show that the new proposed algorithm, with the new proposed Lagrange multipliers up to order four, is suitable for SNR values down to 0 dB and has an improved equalization performance from the residual ISI point of view compared with Reference [49].
2. System Description
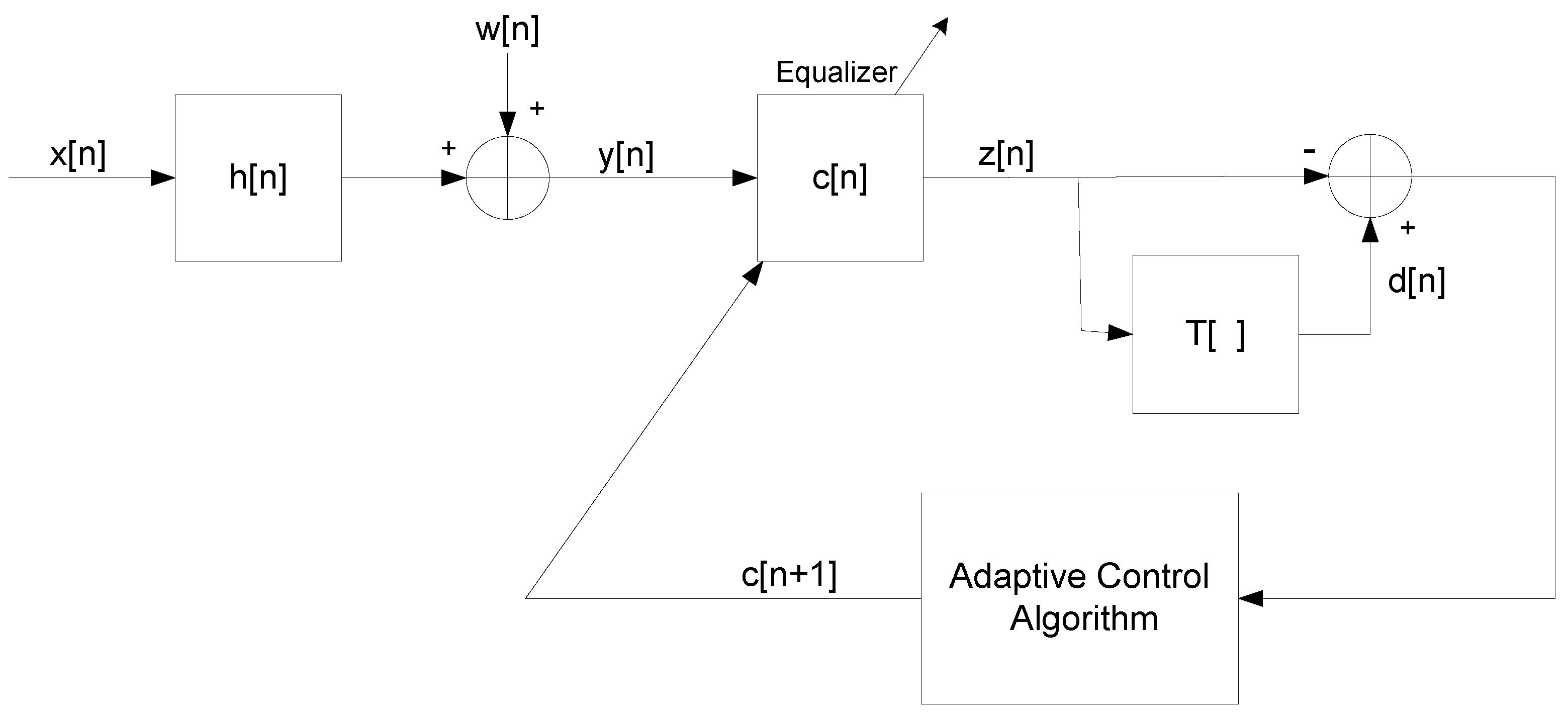
I consider the system from References [20,47,49], illustrated in Figure 1, where I make the following assumptions as were done in References [20,47,49]:
- The source signal is given bywhere and are the real and imaginary parts of , respectively. It is assumed that and are independent and thatwhere stands for the expectation operation.
- The unknown channel is possibly a non-minimum phase linear time-invariant filter in which the transfer function has no “deep zeros”.
- The filter is a tap-delay line.
- The channel noise is an additive Gaussian white noise with variance where and are the variances of the real and imaginary parts of , respectively.
- The function is a memoryless nonlinear function that satisfies the additivity condition:where , are the real and imaginary parts of the equalized output, respectively.
As was described in References [20,47,49], the source input is sent via the channel and is corrupted with channel noise . The ideal equalized output is expressed in Reference [50] as
where D is a constant delay and is a constant phase shift. Therefore, in the ideal case, we could write
where “*” denotes the convolution operation and is the Kronecker delta function. In this paper, I assume, as was also done in References [20,47,49], that D and are equal to zero (please refer to Reference [49] for the explanation). The equalized output is given by
where is the convolutional noise and
In this paper, the ISI is used to measure the performance of the deconvolution process, defined by
where is the component of , given in (8), having the maximal absolute value.
where stands for some error not having the ideal case. The input sequence is estimated with the function and is denoted as . The difference between and the equalized output is denoted as :
This error plays an important role in updating the equalizer’s taps:
where is the conjugate operation on , is the step size parameter, and is the equalizer vector, where the input vector is . The operator denotes the transpose of the function (), and N is the equalizer’s tap length. Another way to update the equalizer’s taps is to use the cost function approach [51]:
where is a predefined function that characterizes the ISI. In the literature [20,47,49,50], we may find the conditional expectation () as a proper option for . According to Reference [20], the conditional expectation for the real valued and noiseless case was obtained via Bayes rules:
where was given by
and the source probability density function (pdf) () was approximated by the maximum entropy density approximation technique:
where is the approximated probability density function and () are the Lagrange multipliers. In the following, for simplicity, I write x and z instead of and , respectively. By using (13)–(15), the conditional expectation obtained by Reference [20] for the real valued and noiseless case is
where
and
Please note that for up to order four, , , , and are polynomial functions of order seven, six, thirteen, and twelve, respectively. According to Reference [20], the Lagrange multipliers were obtained by minimizing the approximated obtained mean square error (MSE) [20] with respect to the Lagrange multipliers. Namely, the Lagrange multipliers were obtained by
where
is the conditional expectation, is the MSE and given by Reference [20] as
For the Lagrange multipliers up to order four, based on (19), we obtain the following equations for and :
3. The New Proposed Expression for the Conditional Expectation
In this section, I present my newly proposed approximated closed-form expression for the conditional expectation based on Reference [20]. In the following, I adopt the assumptions made in References [20,47,49]:
- The convolutional noise is a zero mean, white Gaussian process with variance
- The source signal is an independent non-Gaussian signal with known variance and higher moments.
- The convolutional noise and the source signal are independent.
- The convolutional noise power is sufficiently low.
For justification of the above assumptions, please refer to Reference [49]. In the following, I first consider the real valued case and then turn back to the case where the real and imaginary parts of the input signal are independent (as is the case for the 16QAM source input). According to (19) and (21), we may see that the obtained Lagrange multipliers are depending only on the second leading term associated to the denominator of (16). This may imply that we can use a truncated version of (16) for the approximated conditional expectation expression where the computational burden is automatically reduced compared to (16).
Proposition 1.
where R is the channel tap length, is the k-th tap of the channel , and
In this paper, I propose for the real valued and noisy case the following expression for the conditional expectation with Lagrange multipliers up to order four:
where
and
Proof of the proposed Lagrange multipliers given in (26).
According to Reference [20] (Appendix B), the approximated MSE for the noisy case, valid at the latter stages of the deconvolutional process, may be given as
where
Thus, according to (19), we obtain the following equations for the Lagrange multipliers:
where
The solution of (30) for and as a function of , , and is given in (26). Next, I find closed-form approximated expressions for , , and . When the deconvolutional process has converged and leaves the system with a convolutional noise that can be considered as very low, we may write, according to Reference [52],
Since x and w are independent, by using (32) and the expression for (27) we have
This completes our proof. ▯
Next, I turn to the 16QAM source input. For this case, according to Reference [44], I have that
4. Simulation
In this section, I show via simulation results the efficiency of the truncated expression for the conditional expectation (24) combined with the Lagrange multipliers given in (26). Namely, I show via simulation results the equalization performance from the residual ISI point of view of the new proposed algorithm (with (24) and (26)) compared to the simulation results obtained by the maximum entropy [49] method and Godard’s [53] algorithm. Godard’s [53] algorithm is used for comparison since it is a very efficient algorithm from the equalization performance point of view [28]. In addition, it’s computational burden is very low [28]. For Godard’s algorithm [53], the equalizer’s taps were updated as follows:
where is a positive step size parameter and l stands for the l-th tap of the equalizer. The update mechanism of the equalizer’s taps associated with the recently obtained maximum entropy algorithm [49] was as follows:
with
and
and
According to Reference [49],
and given by
where 〈〉 stands for the estimated expectation, , and are positive step size parameters. , , , , and were set according to Reference [49] as
where
In order to get an equalization gain of one, the following gain control was used according to Reference [49]:
where is the vector of taps after iteration and is some reasonable initial guess. The update mechanism of the equalizer’s taps associated with the new proposed blind equalization method involving the truncated version for the conditional expectation and the newly derived Lagrange multipliers was as follows:
with W given in (37), but with
where
was estimated by
where , and are positive step size parameters. The equalizer’s taps in (46) were updated only if , where is a small positive parameter and
I also used here a gain control according to (45).
In the following, I denote “”, “”, and “” as the algorithms given in References [49,53], and (46), respectively. For the “” and “” algorithms, I used
for initialization.
The following channels were considered:
Channel 2: Normalized Channel 1 with .
Channel 3: Normalized Channel 1 with .
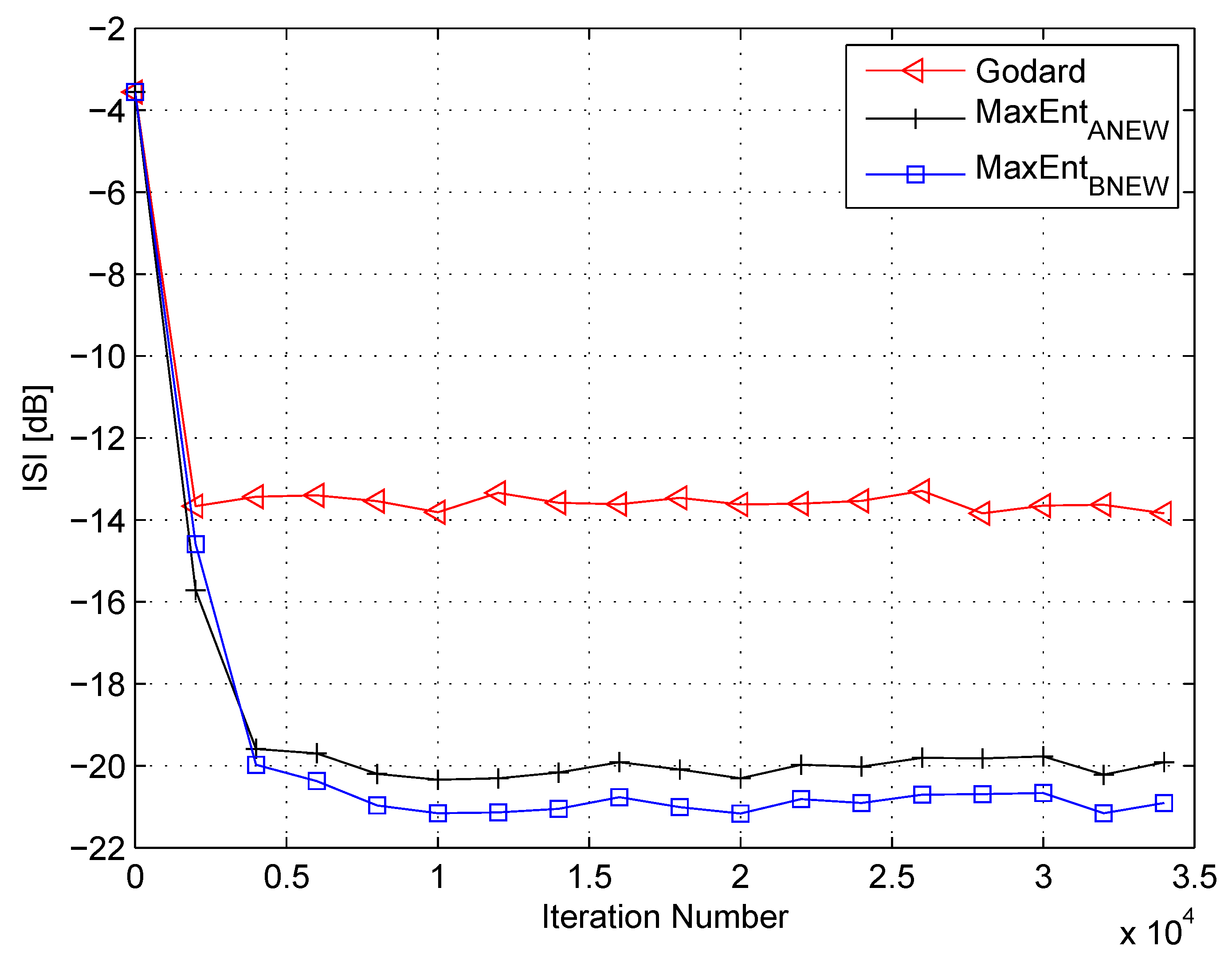
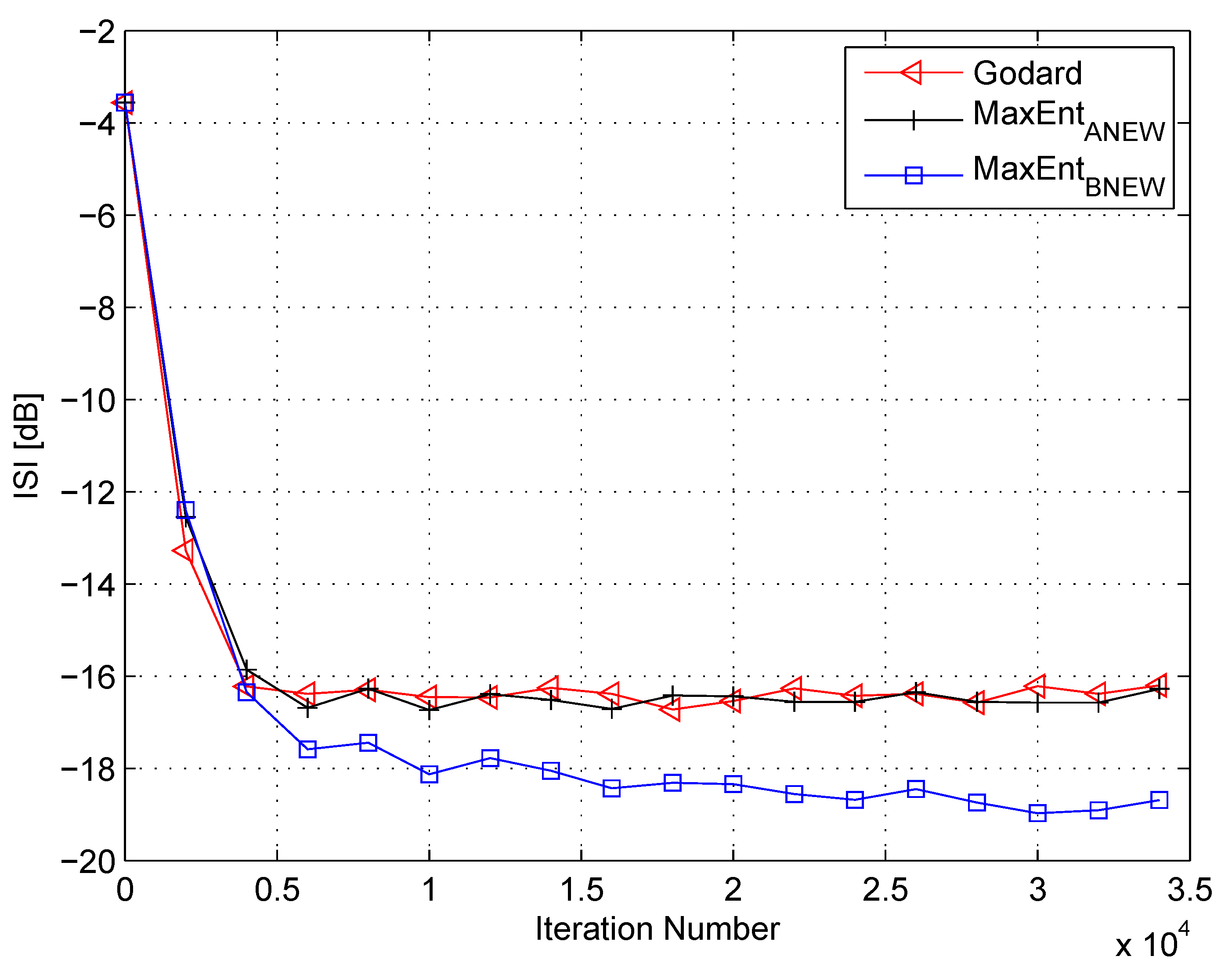
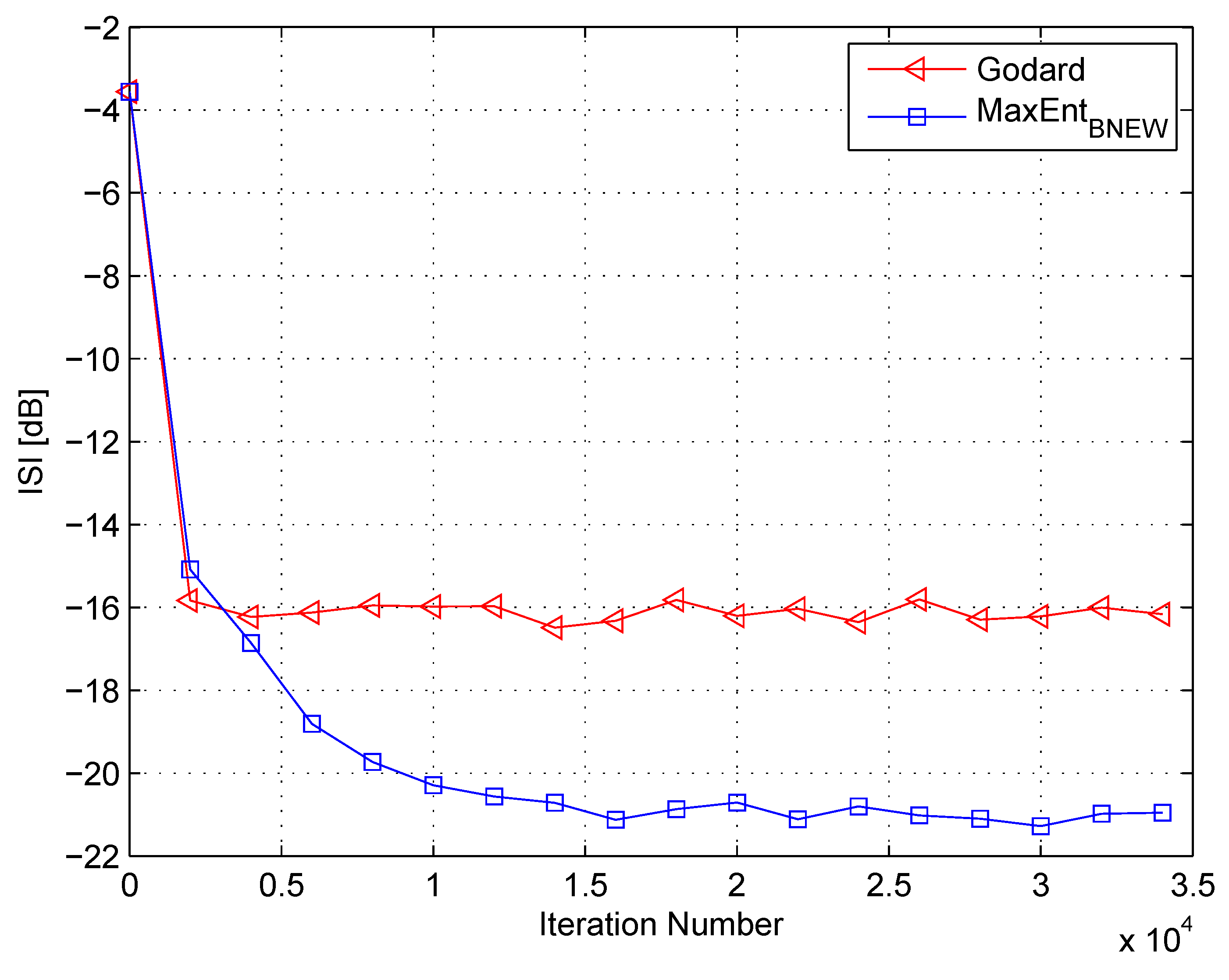
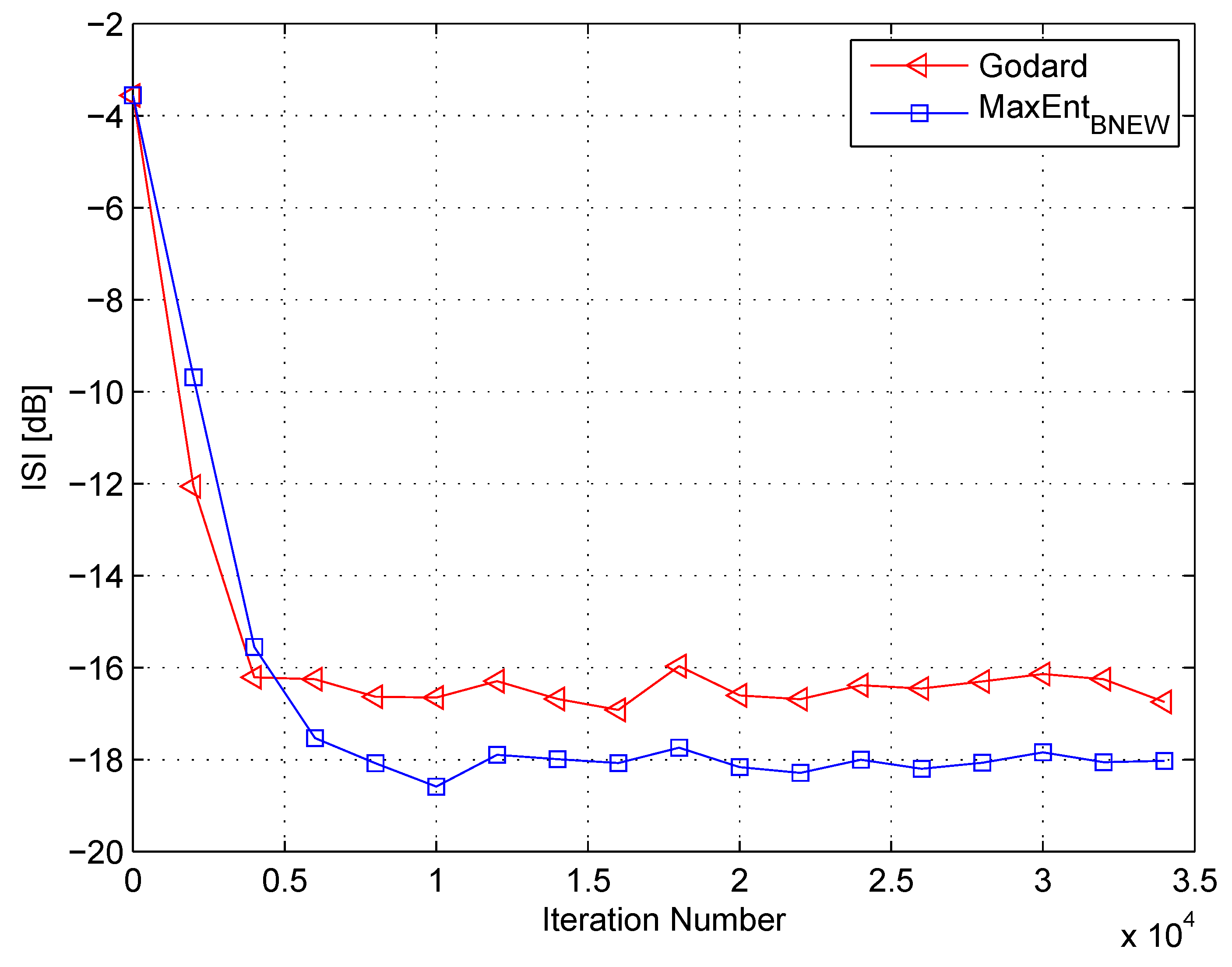
In my simulation, the equalizer’s length was set to 13 taps. For initialization purposes, the center tap of the equalizer was set to one while all others were set to zero. As a source input, I used the 16QAM constellation. The equalization performance comparison between the new proposed equalization method (“” (46)), the maximum entropy [49], and Godard’s [53] algorithm is given in Figure 2, Figure 3 and Figure 4. The equalization performance comparison was carried out for a 16QAM constellation input sent via Channel 1 with SNR values of 10 dB, 7 dB, and 0 dB, respectively. It should be pointed out that the results in Figure 2 and Figure 3 for “” and “” were reproduced from Reference [49]. In addition, please note that according to Reference [49], “” is not applicable for dB. According to Figure 2, Figure 3 and Figure 4, the new proposed algorithm (“” (46)) has a better equalization performance from the residual ISI point of view compared to “” and “”. Next, I tested the proposed equalization method (“” (46)) with Channel 2 and Channel 3 where . Figure 5 and Figure 6 show the equalization performance comparison between the new proposed equalization method (“” (46)) and Godard’s [53] algorithm for the 16QAM constellation input sent via Channel 2 and Channel 3, respectively, with dB. According to Figure 5 and Figure 6, the new proposed algorithm (“” (46)) has a better equalization performance from the residual ISI point of view compared to “”. As a matter of fact, for the case of (Channel 2), the improvement in the residual ISI compared to the results obtained by “” is approximately 5 dB while the improvement in the residual ISI compared to the results obtained by “” for (Channel 3) is only approximately 2 dB. Thus, we may say that the proposed algorithm (“” (46)) has a promising equalization performance from the residual ISI point of view for channels with .
Up to now, I have assumed that the SNR as well as the channel power are known. Thus, we could calculate the required Lagrange multipliers via (48). When the SNR and the channel power are unknown, the , , and cannot be calculated anymore via (48). However, on the basis of (33), we may calculate the required , , and needed for the Lagrange multipliers in (48) from
where is the variance of the real part of and may be simulated as
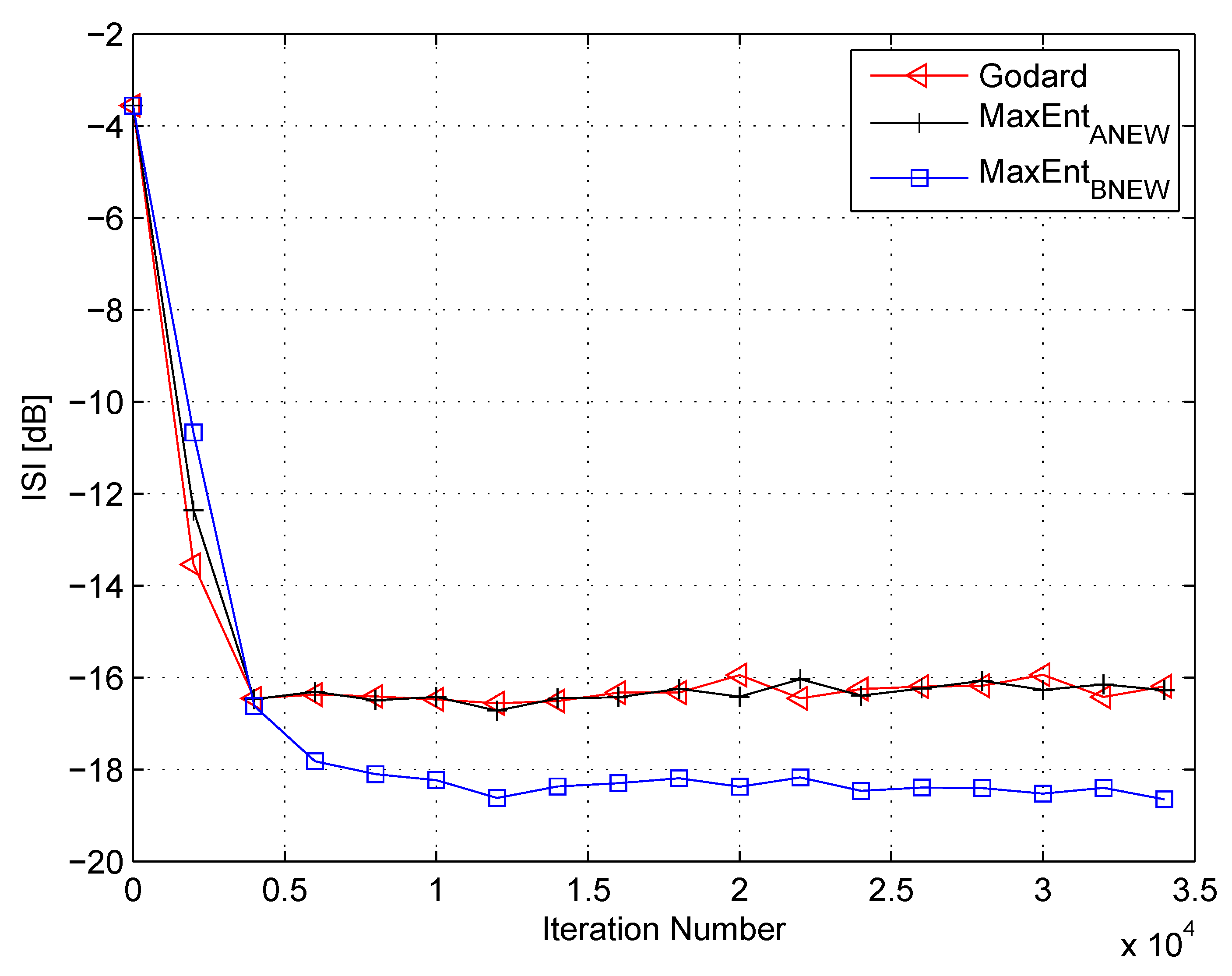
Please note that for the ideal case, when the equalizer has converged, the convolutional noise power tends to zero. Thus, this makes (54) reasonable. In the following, I use (53) and (54) for calculating the Lagrange multipliers related to the “” algorithm. Figure 7 and Figure 8 show the equalization performance of the new proposed equalization method (“” (46) with (53) and (54)), namely the ISI as a function of iteration number for the 16QAM constellation input sent via Channel 1 for SNR values of 10 dB and 7 dB, respectively, compared to the equalization performance obtained from the maximum entropy [49] and Godard’s [53] algorithm. Please note that here the results for “” and “” were also reproduced from Reference [49]. According to Figure 7 and Figure 8, the new proposed algorithm (“” (46) with (53) and (54)) has better equalization performance from the residual ISI point of view compared to the maximum entropy [49] and Godard’s [53] algorithm even when the SNR and channel power are unknown.
5. Conclusions
In this paper, I proposed a new closed-form approximated expression for the conditional expectation (with Lagrange multipliers up to order four) which is actually a truncated version of the expression obtained in Reference [20]. This new proposed expression has a reduced computational burden compared with the previously obtained expressions for the conditional expectation proposed in References [20,47,49]. In addition, I derived new approximated closed-form expressions for the Lagrange multipliers (, ). Simulation results have shown that my newly proposed equalization algorithm, with my newly proposed expression for the conditional expectation and Lagrange multipliers up to order four, is applicable for SNR values down to 0 dB and has an improved equalization performance from the residual ISI point of view compared with References [49,53].
Funding
This research received no external funding.
Acknowledgments
I would like to thank the anonymous reviewers for their helpful comments. In addition, I would like also to thank the editor and the assistant editor for handling my manuscript.
Conflicts of Interest
The author declares no conflict of interest.
References
- Shalvi, O.; Weinstein, E. New criteria for blind deconvolution of non-minimum phase systems (channels). IEEE Trans. Inf. Theory 1990, 36, 312–321. [Google Scholar] [CrossRef]
- Johnson, R.C.; Schniter, P.; Endres, T.J.; Behm, J.D.; Brown, D.R.; Casas, R.A. Blind Equalization Using the Constant Modulus Criterion: A Review. Proc. IEEE 1998, 86, 1927–1950. [Google Scholar] [CrossRef]
- Wiggins, R.A. Minimum entropy deconvolution. Geoexploration 1978, 16, 21–35. [Google Scholar] [CrossRef]
- Kazemi, N.; Sacchi, M.D. Sparse multichannel blind deconvolution. Geophysics 2014, 79, V143–V152. [Google Scholar] [CrossRef]
- Guitton, A.; Claerbout, J. Nonminimum phase deconvolution in the log domain: A sparse inversion approach. Geophysics 2015, 80, WD11–WD18. [Google Scholar] [CrossRef]
- Silva, M.T.M.; Arenas-Garcia, J. A Soft-Switching Blind Equalization Scheme via Convex Combination of Adaptive Filters. IEEE Trans. Signal Process. 2013, 61, 1171–1182. [Google Scholar] [CrossRef]
- Mitra, R.; Singh, S.; Mishra, A. Improved multi-stage clustering-based blind equalisation. IET Commun. 2011, 5, 1255–1261. [Google Scholar] [CrossRef]
- Gul, M.M.U.; Sheikh, S.A. Design and implementation of a blind adaptive equalizer using Frequency Domain Square Contour Algorithm. Digit. Signal Process. 2010, 20, 1697–1710. [Google Scholar]
- Sheikh, S.A.; Fan, P. New Blind Equalization techniques based on improved square contour algorithm. Digit. Signal Process. 2008, 18, 680–693. [Google Scholar] [CrossRef]
- Thaiupathump, T.; He, L.; Kassam, S.A. Square contour algorithm for blind equalization of QAM signals. Signal Process. 2006, 86, 3357–3370. [Google Scholar] [CrossRef]
- Sharma, V.; Raj, V.N. Convergence and performance analysis of Godard family and multimodulus algorithms for blind equalization. IEEE Trans. Signal Process. 2005, 53, 1520–1533. [Google Scholar] [CrossRef] [Green Version]
- Yuan, J.T.; Lin, T.C. Equalization and Carrier Phase Recovery of CMA and MMA in BlindAdaptive Receivers. IEEE Trans. Signal Process. 2010, 58, 3206–3217. [Google Scholar] [CrossRef]
- Yuan, J.T.; Tsai, K.D. Analysis of the multimodulus blind equalization algorithm in QAM communication systems. IEEE Trans. Commun. 2005, 53, 1427–1431. [Google Scholar] [CrossRef]
- Wu, H.C.; Wu, Y.; Principe, J.C.; Wang, X. Robust switching blind equalizer for wireless cognitive receivers. IEEE Trans. Wirel. Commun. 2008, 7, 1461–1465. [Google Scholar]
- Kundur, D.; Hatzinakos, D. A novel blind deconvolution scheme for image restoration using recursive filtering. IEEE Trans. Signal Process. 1998, 46, 375–390. [Google Scholar] [CrossRef] [Green Version]
- Likas, C.L.; Galatsanos, N.P. A variational approach for Bayesian blind image deconvolution. IEEE Trans. Signal Process. 2004, 52, 2222–2233. [Google Scholar] [CrossRef]
- Li, D.; Mersereau, R.M.; Simske, S. Blind Image Deconvolution Through Support Vector Regression. IEEE Trans. Neural Netw. 2007, 18, 931–935. [Google Scholar] [CrossRef] [PubMed]
- Amizic, B.; Spinoulas, L.; Molina, R.; Katsaggelos, A.K. Compressive Blind Image Deconvolution. IEEE Trans. Image Process. 2013, 22, 3994–4006. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tzikas, D.G.; Likas, C.L.; Galatsanos, N.P. Variational Bayesian Sparse Kernel-Based Blind Image Deconvolution With Student’s-t Priors. IEEE Trans. Image Process. 2009, 18, 753–764. [Google Scholar] [CrossRef]
- Pinchas, M.; Bobrovsky, B.Z. A Maximum Entropy approach for blind deconvolution. Signal Process. 2006, 86, 2913–2931. [Google Scholar] [CrossRef]
- Feng, C.; Chi, C. Performance of cumulant based inverse filters for blind deconvolution. IEEE Trans. Signal Process. 1999, 47, 1922–1935. [Google Scholar] [CrossRef]
- Abrar, S.; Nandi, A.S. Blind Equalization of Square-QAM Signals: A Multimodulus Approach. IEEE Trans. Commun. 2010, 58, 1674–1685. [Google Scholar] [CrossRef]
- Vanka, R.N.; Murty, S.B.; Mouli, B.C. Performance comparison of supervised and unsupervised/blind equalization algorithms for QAM transmitted constellations. In Proceedings of the 2014 International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 20–21 February 2014. [Google Scholar]
- Ram Babu, T.; Kumar, P.R. Blind Channel Equalization Using CMA Algorithm. In Proceedings of the 2009 International Conference on Advances in Recent Technologies in Communication and Computing (ARTCom 09), Kottayam, India, 27–28 October 2009. [Google Scholar]
- Qin, Q.; Huahua, L.; Tingyao, J. A new study on VCMA-based blind equalization for underwater acoustic communications. In Proceedings of the 2013 International Conference on Mechatronic Sciences, Electric Engineering and Computer (MEC), Shengyang, China, 20–22 December 2013. [Google Scholar]
- Wang, J.; Huang, H.; Zhang, C.; Guan, J. A Study of the Blind Equalization in the Underwater Communication. In Proceedings of the WRI Global Congress on Intelligent Systems, GCIS ’09, Xiamen, China, 19–21 May 2009. [Google Scholar]
- Miranda, M.D.; Silva, M.T.M.; Nascimento, V.H. Avoiding Divergence in the Shalvi Weinstein Algorithm. IEEE Trans. Signal Process. 2008, 56, 5403–5413. [Google Scholar] [CrossRef]
- Samarasinghe, P.D.; Kennedy, R.A. Minimum Kurtosis CMA Deconvolution for Blind Image Restoration. In Proceedings of the 4th International Conference on Information and Automation for Sustainability, ICIAFS 2008, Colombo, Sri Lanka, 12–14 December 2008. [Google Scholar]
- Zhao, L.; Li, H. Application of the Sato blind deconvolution algorithm for correction of the gravimeter signal distortion. In Proceedings of the 2013 Third International Conference on Instrumentation, Measurement, Computer, Communication and Control, Shenyang, China, 21–23 September 2013; pp. 1413–1417. [Google Scholar]
- Fiori, S. Blind deconvolution by a Newton method on the non-unitary hypersphere. Int. J. Adapt. Control Signal Process. 2013, 27, 488–518. [Google Scholar] [CrossRef]
- Freiman, A.; Pinchas, M. A Maximum Entropy inspired model for the convolutional noise PDF. Digit. Signal Process. 2015, 39, 35–49. [Google Scholar] [CrossRef]
- Shevach, R.; Pinchas, M. A Closed-form Approximated Expression for the Residual ISI Obtained by Blind Adaptive Equalizers Applicable for the Non-Square QAM Constellation Input and Noisy Case. In Proceedings of the PECCS 2015, Angers, France, 11–13 February 2015; pp. 217–223. [Google Scholar]
- Abrar, S.; Ali, A.; Zerguine, A.; Nandi, A.K. Tracking Performance of Two Constant Modulus Equalizers. IEEE Commun. Lett. 2013, 17, 830–833. [Google Scholar] [CrossRef]
- Azim, A.W.; Abrar, S.; Zerguine, A.; Nandi, A.K. Steady-state performance of multimodulus blind equalizers. Signal Process. 2015, 108, 509–520. [Google Scholar] [CrossRef] [Green Version]
- Azim, A.W.; Abrar, S.; Zerguine, A.; Nandi, A.K. Performance analysis of a family of adaptive blind equalization algorithms for square-QAM. Digit. Signal Process. 2016, 48, 163–177. [Google Scholar] [CrossRef] [Green Version]
- Pinchas, M. Residual ISI Obtained by Nonblind Adaptive Equalizers and Fractional Noise. Math. Probl. Eng. 2013. [Google Scholar] [CrossRef]
- Pinchas, M. Two Blind Adaptive Equalizers Connected in Series for Equalization Performance Improvement. J. Signal Inf. Process. 2013, 4, 64–71. [Google Scholar] [CrossRef]
- Reuter, M.; Zeidler, J.R. Nonlinear Effects in LMS Adaptive Equalizers. IEEE Trans. Signal Process. 1999, 47, 1570–1579. [Google Scholar] [CrossRef]
- Makki, A.H.I.; Dey, A.K.; Khan, M.A. Comparative study on LMS and CMA channel equalization. In Proceedings of the 2010 International Conference on Information Society (i-Society), London, UK, 28–30 June 2010; pp. 487–489. [Google Scholar]
- Tugcu, E.; Çakir, F.; Özen, A. A New Step Size Control Technique for Blind and Non-Blind Equalization Algorithms. Radioengineering 2013, 22, 44. [Google Scholar]
- Ali, A.; Abrar, S.; Zerguine, A.; Nandi, A.K. Newton-like minimum entropy equalization algorithm for APSK systems. Signal Process. 2014, 101, 74–86. [Google Scholar] [CrossRef] [Green Version]
- Pinchas, M. The Whole Story behind Blind Adaptive Equalizers/Blind Deconvolution; e-Books Publications Department, Bentham Science Publishers: Sharjah, UAE, 2012. [Google Scholar]
- Haykin, S. Adaptive Filter Theory. In Blind Deconvolution; Haykin, S., Ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1991. [Google Scholar]
- Bellini, S. Bussgang techniques for blind equalization. In Proceedings of the IEEE Global Telecommunication Conference Records, Houston, TX, USA, 1–4 December 1986. [Google Scholar]
- Bellini, S. Blind Equalization. Alta Freq. 1988, 57, 445–450. [Google Scholar]
- Fiori, S. A contribution to (neuromorphic) blind deconvolution by flexible approximated Bayesian estimation. Signal Process. 2001, 81, 2131–2153. [Google Scholar] [CrossRef] [Green Version]
- Pinchas, M. 16QAM Blind Equalization Method via Maximum Entropy Density Approximation Technique. In Proceedings of the IEEE 2011 International Conference on Signal and Information Processing (CSIP2011), Shanghai, China, 28–30 October 2011. [Google Scholar]
- Pinchas, M.; Bobrovsky, B.Z. A Novel HOS Approach for Blind Channel Equalization. IEEE Trans. Wirel. Commun. 2007, 6, 875–886. [Google Scholar] [CrossRef]
- Pinchas, M. New Lagrange Multipliers for the Blind Adaptive Deconvolution Problem Applicable for the Noisy Case. Entropy 2016, 18, 65. [Google Scholar] [CrossRef]
- Nikias, C.L.; Petropulu, A.P. (Eds.) Higher-Order Spectra Analysis a Nonlinear Signal Processing Framework; Prentice-Hall: Enlewood Cliffs, NJ, USA, 1993; pp. 419–425. [Google Scholar]
- Nandi, A.K. (Ed.) Blind Estimation Using Higher-Order Statistics; Kluwer Academic: Boston, MA, USA, 1999. [Google Scholar]
- Pinchas, M. A novel expression for the achievable MSE performance obtained by blind adaptive equalizers. Signal Image Video Process. 2013, 7, 67–74. [Google Scholar] [CrossRef]
- Godard, D.N. Self recovering equalization and carrier tracking in two-dimenional data communication system. IEEE Trans. Commun. 1980, 28, 1867–1875. [Google Scholar] [CrossRef]
Figure 1.
Block diagram of the system.

Figure 2.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for a signal-to-noise ratio (SNR) = 10 dB. , , , , , .
Figure 2.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for a signal-to-noise ratio (SNR) = 10 dB. , , , , , .

Figure 3.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 7 dB. , , , , , .
Figure 3.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 7 dB. , , , , , .

Figure 4.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 0 dB. , , , .
Figure 4.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 0 dB. , , , .

Figure 5.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 2. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 7 dB. , , , .
Figure 5.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 2. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 7 dB. , , , .

Figure 6.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 3. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 7 dB. , , , .
Figure 6.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 3. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 7 dB. , , , .

Figure 7.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 10 dB. , , , , , .
Figure 7.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 10 dB. , , , , , .

Figure 8.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 7 dB. , , , , , .
Figure 8.
Performance comparison between equalization algorithms for a 16QAM source input going through Channel 1. The averaged results were obtained in 50 Monte Carlo trials for an SNR = 7 dB. , , , , , .

© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pinchas, M. A New Efficient Expression for the Conditional Expectation of the Blind Adaptive Deconvolution Problem Valid for the Entire Range ofSignal-to-Noise Ratio. Entropy 2019, 21, 72. https://doi.org/10.3390/e21010072
AMA Style
Pinchas M. A New Efficient Expression for the Conditional Expectation of the Blind Adaptive Deconvolution Problem Valid for the Entire Range ofSignal-to-Noise Ratio. Entropy. 2019; 21(1):72. https://doi.org/10.3390/e21010072
Chicago/Turabian StylePinchas, Monika. 2019. "A New Efficient Expression for the Conditional Expectation of the Blind Adaptive Deconvolution Problem Valid for the Entire Range ofSignal-to-Noise Ratio" Entropy 21, no. 1: 72. https://doi.org/10.3390/e21010072
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.