1. Introduction
In many industrial applications, researchers, engineers, and organizations use computer codes that contain the state of the art of a given branch of engineering. These codes use, in general, physical models that are the state of the art for a given application, for instance CFD (computational fluid dynamics) codes such as ANSYS-CFX or STAR-CD for fluid engineering applications, FEM (Finite Element Method) codes as ANSYS for mechanical engineering applications, thermal-hydraulics codes as RELAP or TRACE for nuclear engineering applications, and so on [
1,
2,
3]. In general, these codes need a set of input data that can be classified as: initial and boundary conditions, geometric data, physical property data, and model parameter data. The methodologies known as BEPU, meaning Best-Estimate Plus Uncertainty, try to estimate the uncertainty in the code response once the uncertainty in the input and model data have been obtained and propagated from the input to the output [
4,
5]. These methodologies provide a set of output results plus their uncertainties in the form of tolerance regions with prescribed levels of coverage and confidence, usually 95/95, meaning a 95% of coverage and 95% confidence. Depending on the type of computational code, the number of uncertain input parameters can be small or large; if the number of uncertain parameters is large, there exist some techniques, as the sensitivity analysis or the PIRT (phenomena identification and ranking table), which allow the reduction of the number of uncertain parameters to only those that have a certain degree of influence on the output results, or, in the case of nuclear engineering, on the critical safety output parameters [
5,
6].
One of the main problems found in this type of work is the determination of the probability distribution of the input and model parameters. Occasionally, we only know the parametric family of the distribution of a given uncertain parameter X, but the distribution parameters
are unknown. So, the set of unknown parameters of the probability distribution function (PDF)
must be determined. Other times, we do not know the distribution of the parameter, but we know some moments of the distributions, so we need a method to obtain the parameter distribution from the partial information that we have on the moments. In addition, it is possible that regulatory restrictions are imposed on some input parameters. For instance, the nuclear regulatory agencies around the world impose the so called ‘technical specifications’ (TS) that must be fulfilled by some operational plant parameters, and surveillances are periodically performed to know if the plant parameters verify these TS [
7,
8]. These additional restrictions can modify the PDF of a given parameter, so we need methods to determine the parameter distributions from the available information and, at the same time, to determine the change in these distributions produced by the TS. Notice that to know if the TS are verified, the parameter values of some components are surveilled periodically and if its values are not within the intervals indicated by the TS, then, modifications are performed to change its values to fulfill the TS. The application of the MEP and the MREP provides a method to determine the PDF of the unknown parameters when partial information is known. The methodology consists of selecting the PDF that maximizes the Shannon information entropy and, at the same time, fulfills the restrictions imposed by the known information in the form of known moments, these ideas were initiated by Shannon and Jaynes [
9,
10,
11,
12] and then were further elaborated by Mead and Papanicolau [
13], Montroll and Shlesinger [
14], Shore and Johnson [
15], among other researchers.
The application of the MEP to engineering problems has been performed in the past by different authors to know the parameter distribution for some cases [
5,
16,
17,
18,
19,
20], when limited information was known about the parameter distribution, for instance, some moments of the distribution and its support interval. This case is studied in this paper and two additional ones that need the application of the MREP: the first case is when new information is available on a given parameter and we need to update the distribution considering the previous one and the new available information, this problem can also be studied by Bayesian methods as in Caticha and Preuss [
21]. The second case is when there are some technical specification (TS) that can have some influence on parameter distribution. These technical specifications can fix some acceptance intervals for some parameters and, also, they establish detailed instructions to perform periodical surveillance to check the fulfillment of the TS [
7,
22].
The main objective of the paper is to develop a methodology to obtain the unknown probability distribution functions of the parameters that enter into BEPU analysis when only partial information is available about these parameters using the MEP, this information could be provided as some known distribution moments or support. A second objective is the updating of the parameter distribution when new information is provided. In this case, the MREP is used to update the PDF, using the old PDF as ranking function. The third objective is how to consider the effect of the technical specifications imposed by regulatory authorities on the probability distributions of the input parameters that must fulfill these TS. Finally, a four objective is to develop tools to apply these developments to real cases found in the applications. These developments are of relevance for present and future applications of BEPU and uncertainty quantification of the results of many engineering applications.
The aim of the paper is to assemble, in a single paper, the basic ideas of the maximum entropy and the maximum relative entropy principles, and the applications of these principles to solve common problems found in BEPU engineering analysis, including the technical specifications imposed by the regulations. In addition, a few key deductions have been explained with detail in order that people learns how to apply these techniques to solve specific problems.
The paper has been organized as follows:
Section 2 gives a brief introduction on uncertainty quantification in engineering codes. The goal of this section is to analyze the fields where the principles of maximum entropy and maximum relative entropy can be applied.
In
Section 3.1, we explain how to apply the principle of maximum entropy to the determination of the probability distribution function when some moments of the distribution are known; whereas in
Section 3.2, we explain the application of the maximum relative entropy to update PDF when new information is available; finally, in
Section 3.3 it is explained the application of the MREP to the determination of the PDF considering the technical specifications imposed by regulatory authorities.
In
Section 4, we give some examples of the application of the MEP and the MREP to some cases that can appear in the applications.
Section 4.1 shows the application of the MEP and the MREP to the case of known support
and previously known mean
, and variance
when the TS impose an acceptance interval
with coverage
and confidence
. In
Section 4.2, we explain the application of the MREP to several cases with previously known distributions when new information is known with and without technical specifications (TS). In
Section 4.3, we explain the application of the MREP to the case of a parameter with a previous truncated Gaussian distribution, for which the updated data have the same mean and support but different variance. Finally,
Section 4.4 of this paper shows the results obtained applying the MEP to several cases found in the applications.
In
Section 5, we explain the programs that have been built to apply the previous development to some real cases, also in this section we display some applications of the previous programs to some particular cases.
Finally, in
Section 6 we discuss the main findings and conclusions of the paper.
3. Application of the Maximum Entropy Principle and the Maximum Relative Entropy Principle to the Determination of the PDF with and without Technical Specifications
3.1. Application of the MEP to the Case of Knowledge of Some Moments of the Distribution and Its Support
When the probability distribution function of a given parameter
X with continuous distribution is unknown and some moments of the parameter distribution are known, then, we apply the maximum entropy principle (MEP) to obtain the parameter distribution following the ideas of Jaynes [
11,
12]. If
denotes the probability density function of the random parameter
X, and
the cumulative distribution function, Claude Shannon defined the concept of information entropy H as a measurement of the uncertainty associated to the result of a given process [
9]. If
X has a compact support, i.e., the random variable
X can take values between
a and
b, with
b >
a, being [
a,
b] the distribution support; then the Shannon information entropy is defined by the expression [
5,
9,
10,
16]
Usually, we have statistical information about some moments of the PDF, defined in the general form
In general, the functions define the different moments of the distribution function of the parameter , where the index runs from 1 to the number n of previously known moments, the index 0 is reserved for the normalization condition of the PDF, i.e., when we make , and
The problem to be solved in information theory when applying the MEP is to obtain the PDF expression
that maximizes the information entropy and, at the same time, obeys the set of restrictions displayed in Equation (5). To solve this problem, variational calculus is generally used and, first, we build the following functional
that includes the restrictions of Equation (5) by means of the Lagrange multiplier method
The variational calculus looks for the PDF
that maximizes the information entropy and is consistent with the available constraining information. So that one looks for the PDF
and the Lagrange multipliers
values such that we have an extreme of the functional
, and at the same time the set of restrictions (5) are satisfied. To find this extreme, one considers an arbitrary perturbation
that vanishes at the end points
a and
b of the support interval. According to the variational calculus, the first variation
of the functional
is given by
Performing the calculations in Equation (7) because of Equation (6) yields
Due to the arbitrary character of the perturbation
the term inside the brackets in Equation (8) must be zero so it is obtained for the PDF of the parameter the following expression
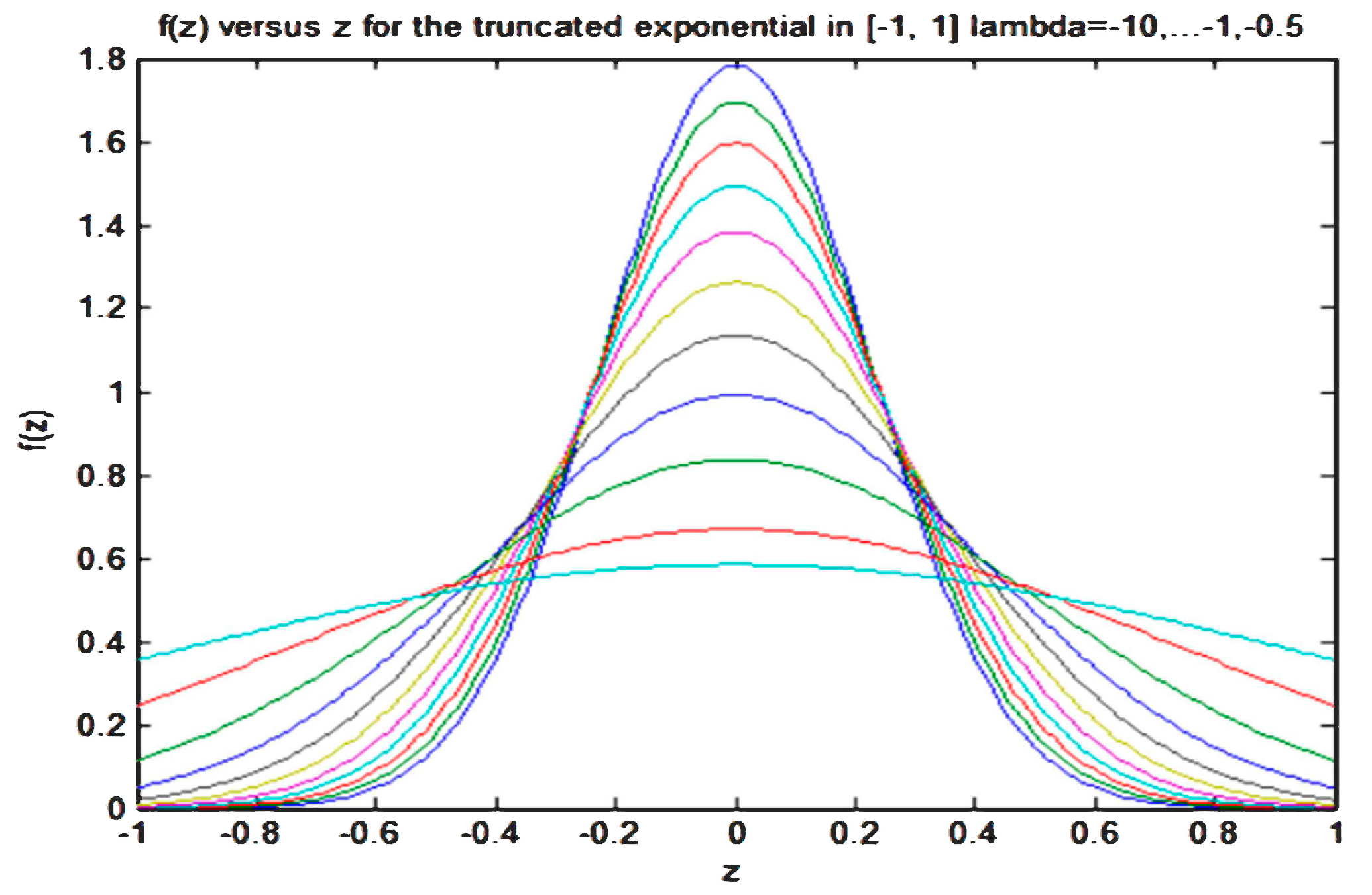
The values of the constants are obtained from the available information on the distribution moments given by the set of Equation (5). In general, to obtain the parameter values of it is necessary to solve a non-linear system of algebraic equations as will be shown later.
3.2. Application of the Maximum Relative Entropy (MREP) to the Case of New Updating Information
The principle of maximum relative entropy (MREP) can be applied in the following two cases. The first one is to update a previous or ‘a priori’ PDF denoted by of a given parameter when new information is available, this information can be provided as new data or moments of the distribution. The second case is when a regulatory body impose some specifications or restrictions on the parameter values that modify the parameter distribution, this second case will be studied separately.
Let us now study the first case, assuming that the parameter follows an unknown probability density
in the support interval
. Let us assume that we have a previous estimation or ‘a priori’ estimation
of the true PDF. Then, at a later time or ‘a posteriori’, we have obtained additional information as moments or data of the unknown PDF. Therefore, we need to update the probability distribution considering both the previously known distribution and the new information or data available on the parameter. This goal can be achieved using the principle of the maximum relative entropy (MREP). Caticha and Preuss [
21] used this principle to develop updating methods that are systematic and objective, they arrive to the conclusion that the unknown probability distribution
should be ranked according to its relative entropy with respect to the previously known PDF
, this means
The new information generally comes as a set of known moments
of the unknown distribution
given by
where the new moment values could be the same or different values from the previous ones, so we distinguish the new values with a prime, also the number of new moments
could be different. To maximize the relative entropy subject to the new restrictions we build the new functional
with Lagrange multipliers
and moments
as
Then, we use variational calculus again to obtain the PDF that maximizes the relative entropy and, at the same time, satisfies the updated moment values, i.e., we set the first variation of the functional
to zero
This calculation yields, because the arbitrary character of the perturbation
, the result
The set of updating parameters is obtained from the conditions (11). We notice that, by using the maximum relative entropy principle, we update the old PDF by multiplication by a new updating or correcting function .
3.3. Application of the Maximum Relative Entropy to the Case of Imposing Restrictions or Technical Specifications by a Regulatory Body
In some branches of engineering, as nuclear engineering, some operational parameters are subject to technical specifications (TS) set by the regulatory authorities. For instance, the opening pressure of the safety and relief valves of a nuclear plant must lie inside the interval
, and a similar interval for closing, where the value
denotes the reference pressure value at what a specific valve should open when the pressure reaches this value, the reference value for closing is in general different than for opening. Therefore, the TS fixes the acceptance interval limits for the opening or closing pressures during the periodical surveillances. If during the periodic surveillance the opening or closing pressures are outside the limits fixed by the TS, the conditions of the valve are modified to fulfill the TS [
26,
27].
Technical specifications are intimately related to deterministic safety analysis. Safety analyses are aimed to prove that the plant operation allowed by TS is safe enough. For traditional conservative analyses, the TS give the regions, in the input parameter ranges, where the safety analyses are valid and give acceptable results (i.e., results that fulfill the regulatory acceptance criteria). In fact, conservative safety analyses are performed, setting the operational parameters on their TS limits.
However, things are different when the analyses are performed with BEPU methodologies. If we assume that some operational parameters are assigned probability distributions, an important point is how to choose the distributions in order to ensure that the allowed operation is being evaluated.
This problem of the compatibility of TS and BEPU methodologies has not received enough attention in the regulatory and academic community. A first approach is found in [
22], where regulatory criteria are proposed on the probability distributions assigned to operational parameters so that it is ensured that the BEPU analyses adequately ‘explore’ the acceptance region defined by the TS.
Therefore, when assigning probability distributions to an input parameter controlled by TS, we can distinguish two different problems:
- (1)
Assigning a distribution to the parameter that represents the normal operation of the plant. In this case, TS acts as a restriction imposed to the normal plant values. This type of distribution is useful if we want to make BEPU analysis of the normal operation of the plant.
- (2)
Assigning a distribution to the parameter that represents the allowed operation, rather than the normal operation, of the plant. In this case, we need a fictitious distribution for the parameter, producing high enough probability to be in regions close to the TS limits. This approach is useful in licensing analysis, when we want a BEPU analysis of the allowed operation of the plant.
In a sense, options (1) and (2) are complementary. Reference [
22] was devoted to option (2), because it refers to the licensing analysis, where operation allowed by TS is evaluated. In the present paper, we study option (1), useful for the analysis of normal plant operation. However, the application of the methods here described to option (1) is straightforward; also, the methods developed in this paper can be applied to option (2), as explained later in
Section 5.4.
In probabilistic analysis BEPU, it is assumed that the parameter values are inside the interval [
L,
U] with a coverage probability of
and a degree of confidence of
. Normally, these probabilities are expressed in % and are 95/95, what means that we have a coverage probability of 95% with a confidence of 95%. Therefore, for a number of cases N, or data sample size N, we have a probability p of the random parameter to belongs to the acceptance interval [
L,
U] when we have a coverage probability
and a confidence of
. The way to obtain the
p-value is deduced and explained in
Appendix A, and involves solving the following equation
where
and
is the ceiling function of y;
, is the incomplete beta function with parameters
x,
a, and
b, see
Appendix A for more details.
and
are respectively a coverage and a confidence level, with values close to 1 (typically 0.95). Notice that the coverage and confidence levels in (15) refer to the fulfillment of the TS by an input parameter, and are conceptually different from the coverage and confidence levels in (3) that refer to the output of the BEPU analyses. It is important to remember that the size of the Monte Carlo sample,
, is obtained from the tolerance level in (3).
Condition (15) means that a fraction
of the
N sample values falls into the acceptance interval [
L,
U] with a probability
. Here we have followed the approach used in [
22] for assignation of distributions.
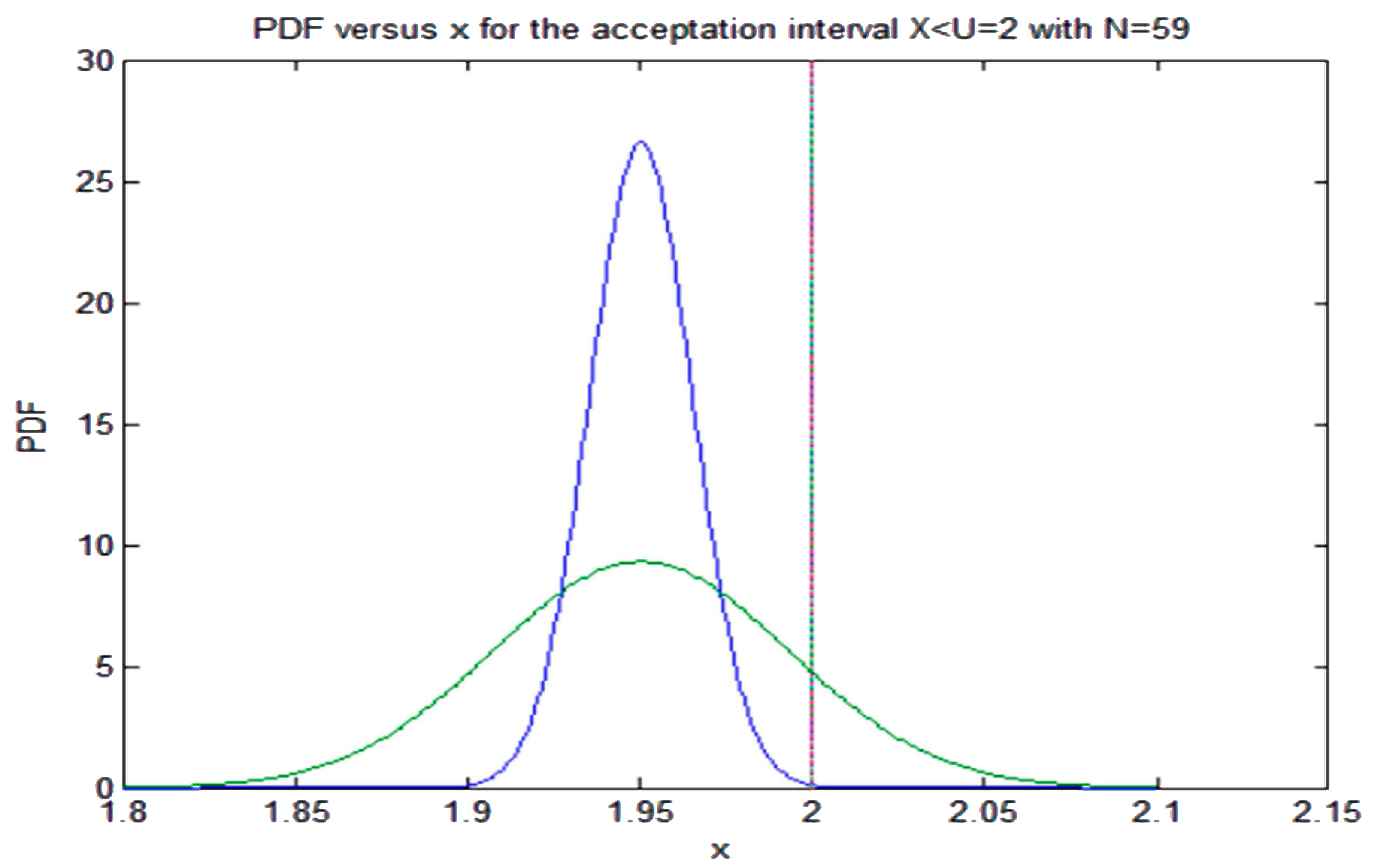
For instance, the solution of Equation (15) using the inverse of the incomplete beta function, i.e., “betaincinv” of MATLAB with
N = 93,
gives
p = 0.9786. Therefore, in this case, the additional restriction that we have on the PDF and that is imposed by the technical specification is
The condition (16) can be expressed if the support of the distribution is
as follows
where
is the Heaviside function that is zero for
, and 1 for the rest of values;
is the Heaviside function that is zero for
, and 1 for the rest of values.
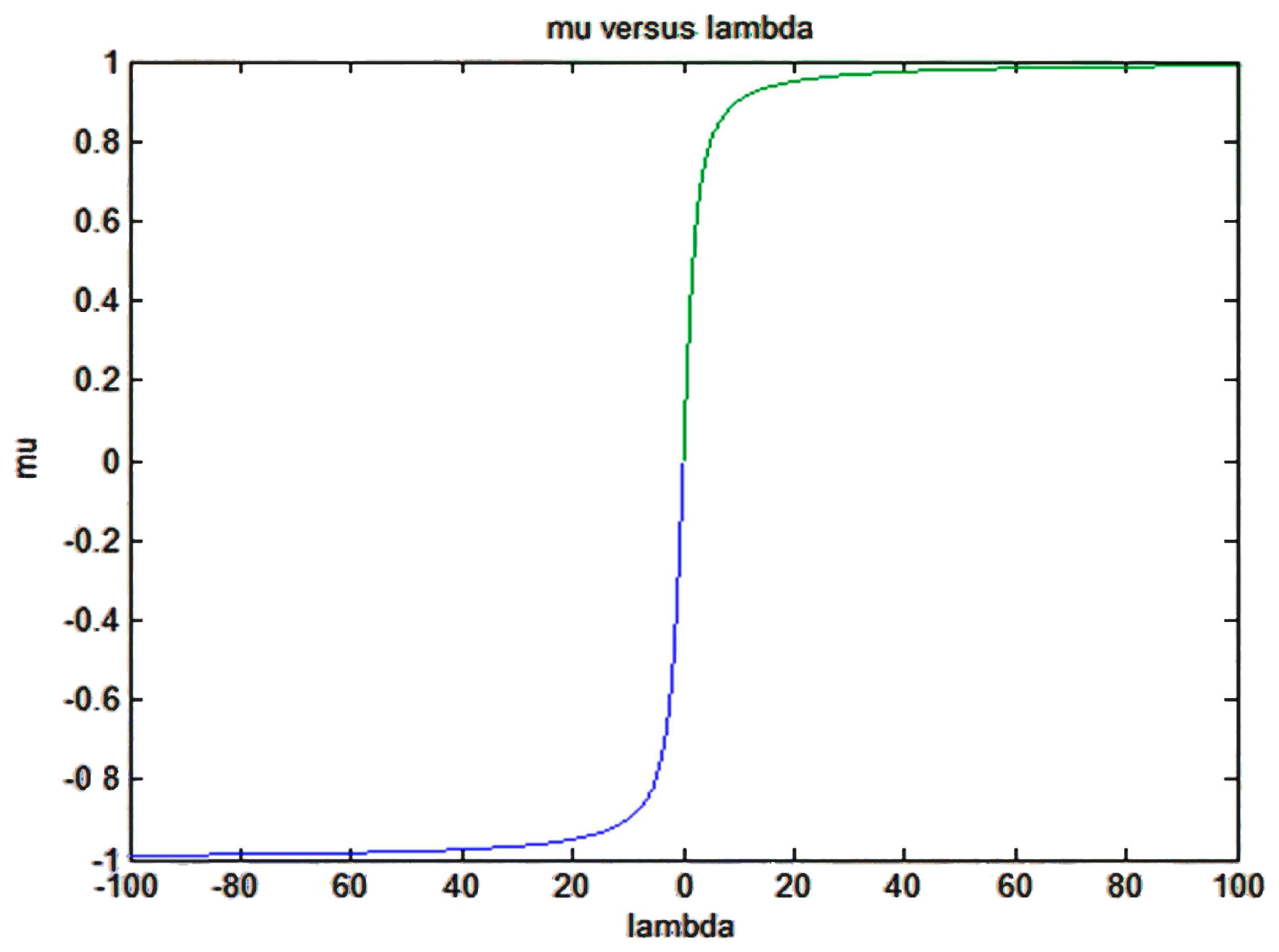
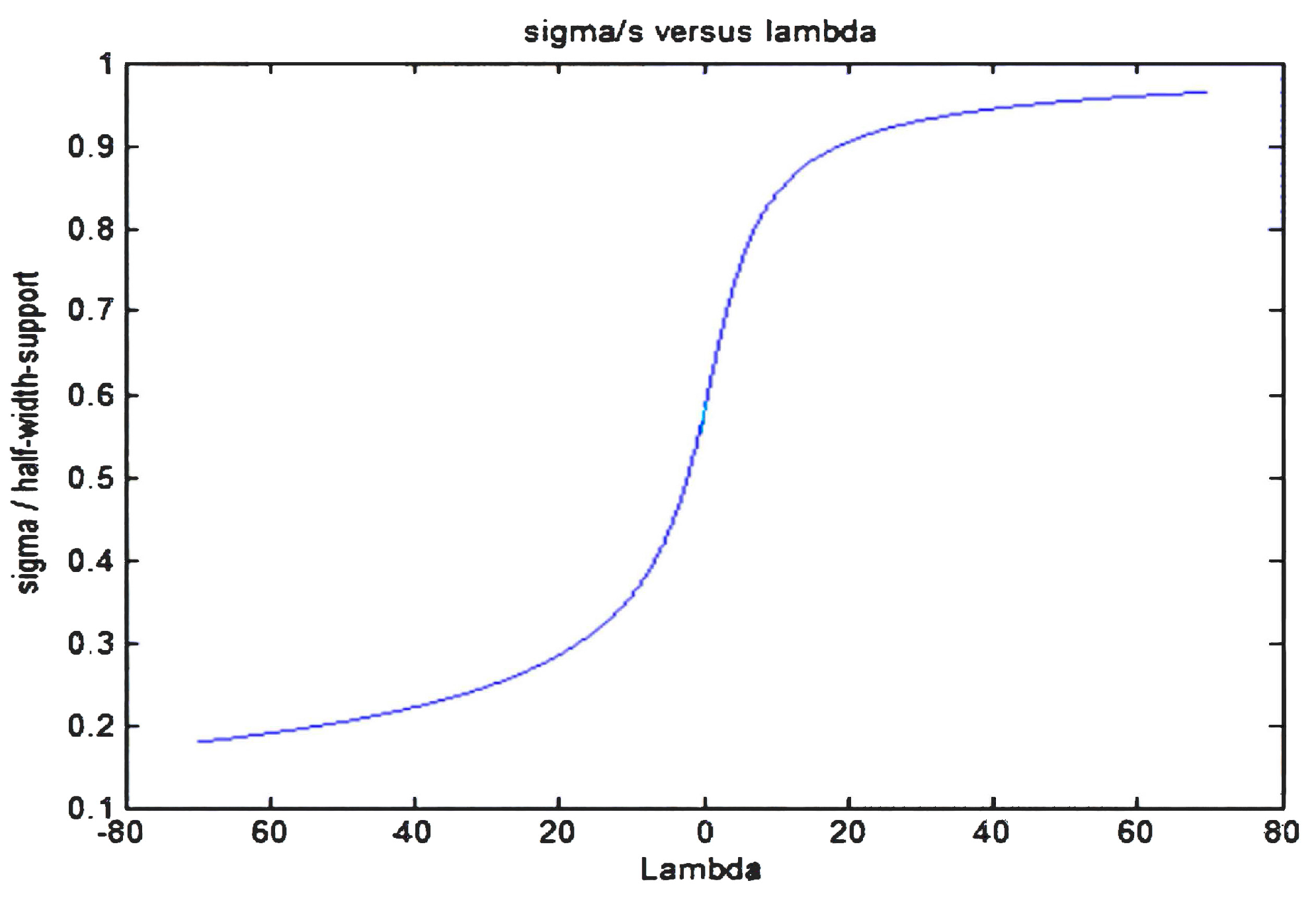
The question is that the TS through the surveillance and repairing actions modifies the parameter distribution in such a way that some parameter of the distribution could be modified to fulfill Equation (16), normally this parameter is the variance of the distribution that it is changed to comply with (16). The regulatory authority could modify the value of
p given by (15) to perform a conservative analysis [
22]. This last point will be discussed later in
Section 5.4.3. Let us discuss the general conditions that must verify
, first the function must be a continuous function in order to have an unambiguous probability value for each x, second for these kind of problems influenced by the TS, the average value of the distribution in general does not change for symmetrical distributions because this value represents the reference value of the TS—i.e., the reference pressure for opening or closing the valve—although this statement in some particular cases could change. Also, some moments such as the variance related to the width of the distribution could change. The way to proceed is as follows, first with the known support and the distribution moments we apply the MEP and we determine the previous probability distribution,
Second, we build the functional that considers the moments that can change as unknowns and take into account the TS condition (17) and the known moments
Proceeding as in the previous subsection—i.e., equating to zero the first variation—yields the following expression for the new PDF that considers the TS and maximizes the relative entropy
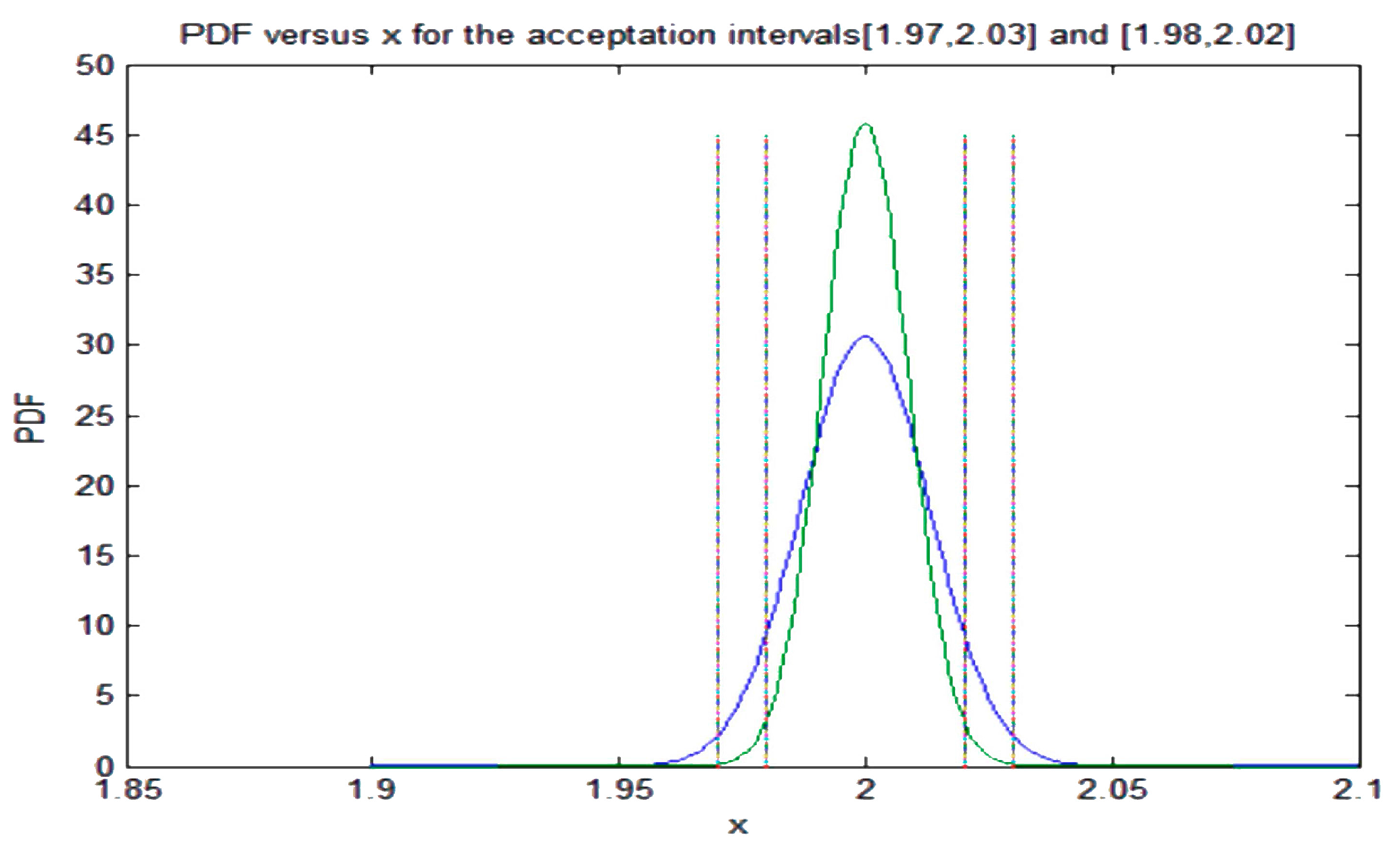
The unknown parameter values of the new PDF are obtained from the updated conditions (11), the TS condition (16), and the continuity of at and . Some examples will be shown in the next section.
6. Discussion and Conclusions
Realistic calculations in many engineering fields involve the use of Best-Estimate codes, that use the state of the art models to predict the values of a set of magnitudes that need to be calculated to know if these output magnitudes fulfill some restrictions or does not surpass some limiting values [
36,
37]. In general, some of the input data and model parameter are uncertain, so the predictions of these codes are, in general, subject to uncertainty, and it is necessary to express the output results as tolerance regions with a coverage value and a given confidence, normally 95/95. Tolerance intervals are built for scalar magnitudes. Many realistic methodologies build the tolerance intervals from the output results using order statistic [
5,
8,
36,
37]. This topic is especially true in nuclear engineering applications, where the consequences of errors in the calculations, or the design, performed with these thermal-hydraulic or neutronic codes are more severe. However, the same kind of methodology can be applied to other codes, as CFD and FEM, with other applications, where some input parameters are uncertain. One alternative to BEPU approach is by introducing ultraconservative models and assumptions that predict the output variables with a high degree of conservatism, for instance, in nuclear calculations, there exist the conservative appendix K approach for Nuclear Safety Analysis. Another issue of importance, that is normally circumvented, is that some of the input parameters are sometime subject to TS involving periodic surveillance to see if the parameter belongs to a prescribed acceptance interval [
7,
22]. The problem is how to assign probability distributions to these operational parameters controlled by TS. This topic is generally omitted in the discussion and analysis of this kind of methodologies, and was raised and studied for the first time in [
22]. Two approaches may be conceived for this problem, depending if the PDF to be assigned represents the allowed operation or the normal operation of the plant. The first case (Option 2 of
Section 3.3) is the important one from the regulatory standpoint, because it is needed in licensing applications, and was the focus of [
22]. The second case (Option 1 of
Section 3.3) should be needed in the case of fully realistic simulation scenarios, and is assumed through the present paper although in
Section 5.4.3 it is outlined the possibility to extend the approach developed in this paper to Option 2. We have tried to give a first approach to solve this problem trying to know the way in which the TS can affect the PDF. This systematic approach has been carried out considering the previous PDF as a ranking PDF during the application of the MREP, in the sense given by Caticha and Preuss [
21], and considering the acceptance interval imposed by the TS, as a restriction in the function though an additional term with an unknown Lagrange multiplier that must be obtained ‘a posteriori’, as we have shown in this paper.
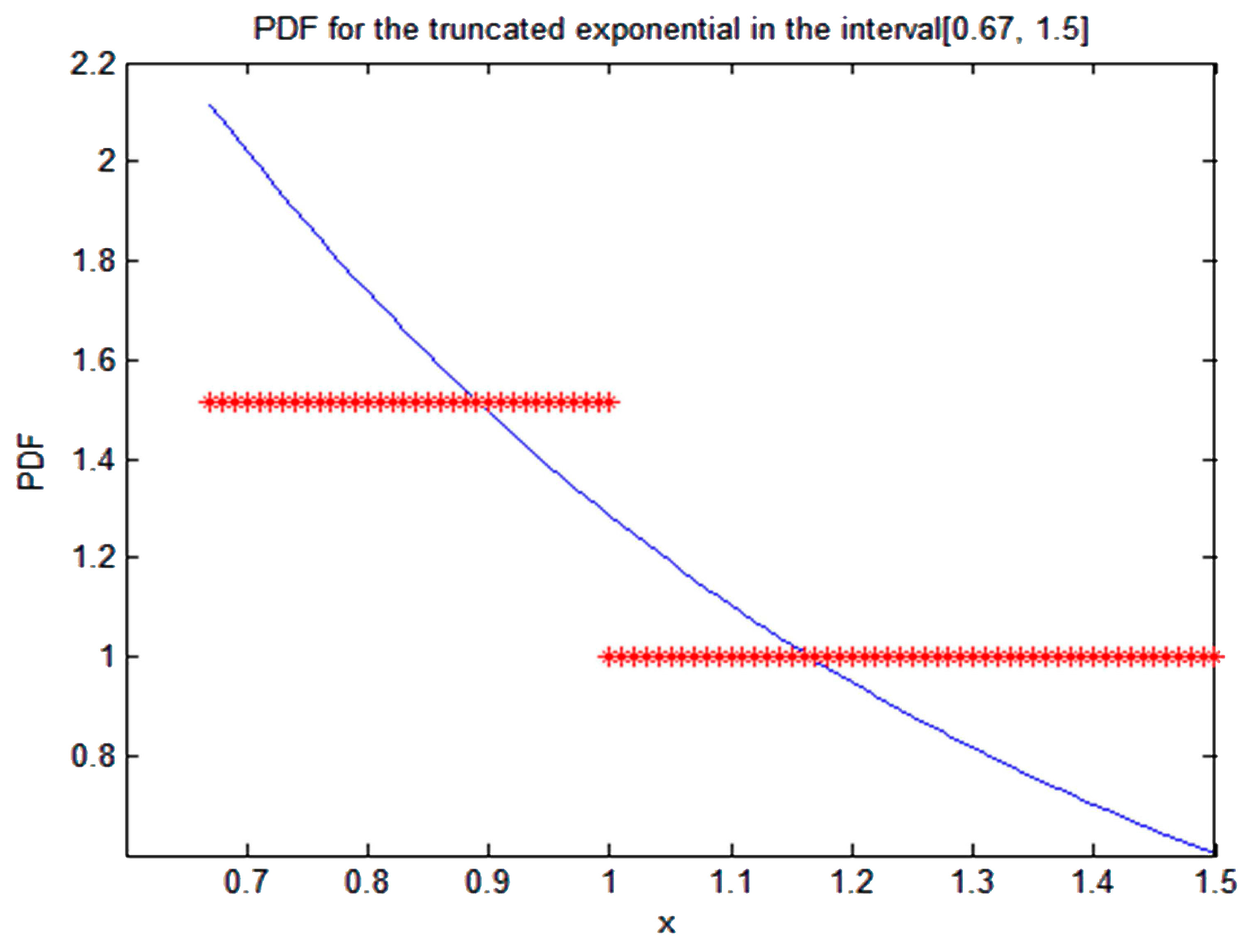
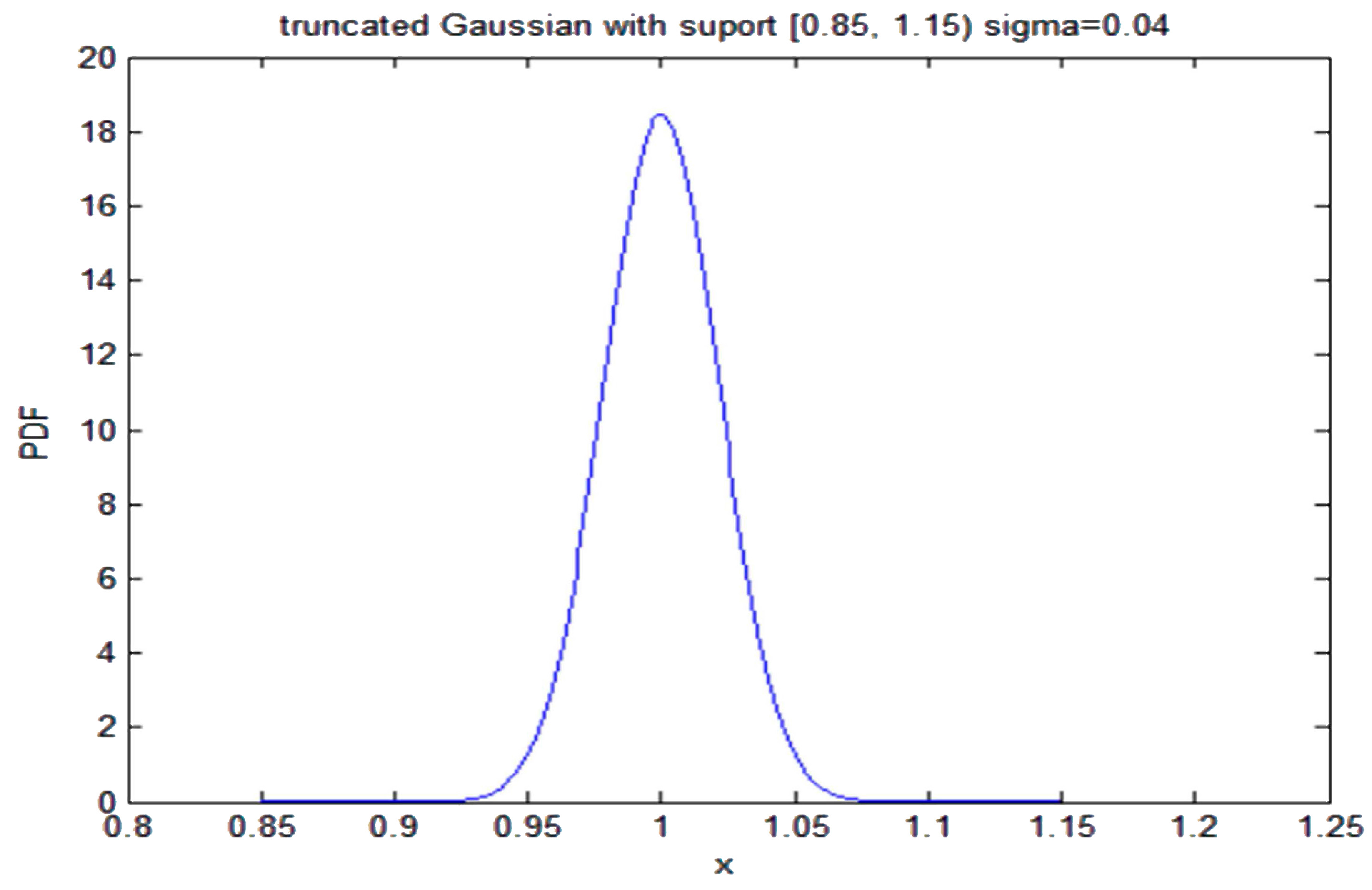
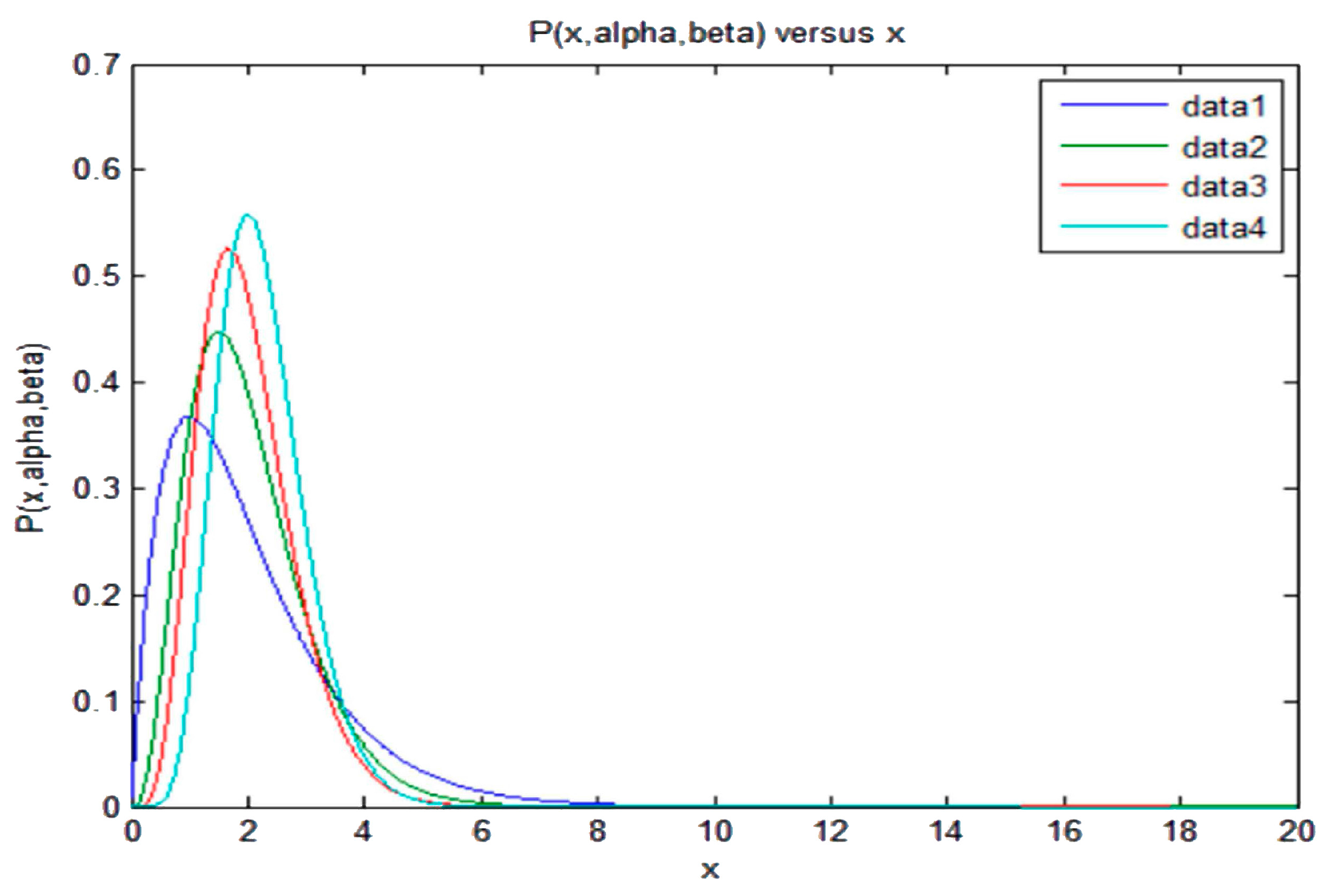
In general, the determination of the Lagrange multipliers that appear when obtaining the PDF by application of the MEP requires solving a non-linear equation, as Equations (49) or (51) for the truncated exponential, or Equation (55) for the truncated Gaussian. In some cases of non-truncated distributions, as in Equation (76), the Lagrange multipliers have been obtained analytically. In the case of the gamma PDF with three constraints, the Lagrange multipliers can be obtained numerically solving a non-linear equation system, as showed by Woodbury [
38].
Normally, in the applications of BEPU type methodologies, there are two options to build the input or model parameter distribution. The first one is when we know the distribution of the input or model parameter. This distribution has been obtained from some experimental set of data values by performing test with the data using the empirical distribution function (EDF), as explained in Stephen’s paper [
31]. This is the method that follows the program GEDIPA [
5] explained in
Section 5.1. The second option is when we have only partial information about the parameter, as could be the support of the distribution [
a,
b] and some of their moments. In this second case we have two options, to apply the MEP or the MREP, if we have some previous PDF to rank the new probability distribution taking into account the information available by building a functional that include the known moments of the distribution, as a set of restrictions. The application of the MEP when we know the support and some moments has been performed in a set of cases, as explained in
Section 4.4. These cases have been incorporated to the program UNTHERCO that performs the Monte Carlo sampling on the PDF when partial information is known [
5] and builds the PDFs that result from the application of the MEP. In
Section 5.5, we provide some examples of the application of the MEP to build the PDF.
The application of the MREP for updating the PDF, when new information is available and using the previous PDF as a relative ranking function for the new probability distribution, provides, in general, solutions with physical sense, as shown in the cases developed in
Section 4.2.1,
Section 4.3, and
Section 4.4, of this paper. This result agrees with that of Caticha and Preuss [
21], that established a set of three axioms for physical systems, and arrived at the overall conclusion that the updated probability distributions should be ranked relative to the previously known distribution according to their relative entropy. The consequence of this fact is that the MREP gives a high preference to the updated distributions
, that vanish whenever the previous PDF
does. An example of this issue was studied by Muñoz-Cobo et al. in appendix II-2 of reference [
5], In this case, the previous distribution was Gaussian, with a mean and variance of
, respectively. The new information provided was the same support, and different mean
, and no more new information was provided. The result obtained was that the new distribution was again a Gaussian one with different mean
and the same variance, so the new distribution vanishes at the same points
and
, where the previous distribution does. Application of the MREP performed in cases 4.3 and 4.4 of this paper confirms again that the new updated distributions vanish whenever the previous distribution does.
The influence of the TS on the PDFs has been studied in a very broad context. The first case studied is how the PDF must be changed to fulfill the TS in a probabilistic sense, with coverage and confidence 95/95, when we have a sample of
N cases for BEPU analysis obtained from Wilks’ formula. In
Appendix A, we deduced the probability
p of the parameter
X to belongs to the acceptance interval [
L, U] when performing a BEPU, analysis with
N cases. If the parameter fulfills the TS the PDF does not need to be changed unless to be required by the regulatory body to check a more conservative approach, as studied in the case developed in
Section 5.4.3. The second case is when the PDF does not fulfill the TS, and the PDF must be changed to fulfills the TS, the first step is to obtain the probability
p of the parameter to belong to the acceptance interval [
L, U], as explained in
Appendix A. In this case, we have an additional restriction in the functional imposed by the TS that tells us that the probability of the new PDF to belong to the [
L, U] interval is
p. This new restriction is added to the other restrictions as a new term in the functional
, that contains the relative entropy and the set of restrictions imposed by the moments plus this new restriction imposed by the TS. Applying the MREP, we obtained a new PDF that maximizes the entropy and considers as ranking function for the relative entropy the PDF that is obtained without considering the effect of the TS. Using variation calculus—i.e., maximizing the relative entropy by
—we obtain the new PDF. To obtain the parameter values of this PDF, one must solve one system of equations, as shown in
Section 3.3, and with several examples given in
Section 5.2,
Section 5.3 and
Section 5.4 for different kinds of acceptance intervals imposed by the TS and different kind of conditions.
As a final conclusion, we can say that the main contribution of the paper is the development of a methodology to determine uncertain PDF based on MEP and MREP in the cases of known moments of the distribution and its support, new updating information, and technical specifications (TS) imposed by the regulations. The influence of the TS on the PDF was previously circumvented and in this paper a general analysis on this issue has been performed. Also, several examples have been shown on the application of this methodology to PDF updating that must fulfill technical specifications as explained in
Section 5.2,
Section 5.3 and
Section 5.4. Finally, three computational tools have been developed (GEDIPA, UNTHERCO, and DCP) for the implementation of the MEP and the MREP in BEPU analysis.
The future avenues of research in this matter are: (i) to include the possibility to handle errors in the data into the MEP and the MREP principles to reconstruct the PDF of the parameters in the line started recently by Gomes-Gonçalves, Gzyl and Mayoral [
39]; (ii) to extend the examples of updating using the MREP to cases in which the previous PDF is the gamma distribution or even more complex ones as the four parameters exponential gamma distribution [
40]; (iii) to extend the analysis to PDF not considered in this paper as the double exponential distribution, the Fisher distribution and the logistic distribution; (iv) to generalize the updating methodology including moments and data following the ideas of Adom Giffin [
41]; (v) to study more deeply Option 2 to assign PDF to operational parameters controlled by TS.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}