Comparing Markov Chain Samplers for Molecular Simulation


Department of Computer Science, Purdue University, West Lafayette, IN 47907, USA
*
Author to whom correspondence should be addressed.
†
Current address: School of Mathematical and Statistical Sciences, Arizona State University, Phoenix, Tempe, AZ 85287, USA.
Entropy 2017, 19(10), 561; https://doi.org/10.3390/e19100561
Submission received: 6 September 2017
/
Revised: 17 October 2017
/
Accepted: 19 October 2017
/
Published: 21 October 2017
(This article belongs to the Special Issue Understanding Molecular Dynamics via Stochastic Processes)
Abstract
:Markov chain Monte Carlo sampling propagators, including numerical integrators for stochastic dynamics, are central to the calculation of thermodynamic quantities and determination of structure for molecular systems. Efficiency is paramount, and to a great extent, this is determined by the integrated autocorrelation time (IAcT). This quantity varies depending on the observable that is being estimated. It is suggested that it is the maximum of the IAcT over all observables that is the relevant metric. Reviewed here is a method for estimating this quantity. For reversible propagators (which are those that satisfy detailed balance), the maximum IAcT is determined by the spectral gap in the forward transfer operator, but for irreversible propagators, the maximum IAcT can be far less than or greater than what might be inferred from the spectral gap. This is consistent with recent theoretical results (not to mention past practical experience) suggesting that irreversible propagators generally perform better if not much better than reversible ones. Typical irreversible propagators have a parameter controlling the mix of ballistic and diffusive movement. To gain insight into the effect of the damping parameter for Langevin dynamics, its optimal value is obtained here for a multidimensional quadratic potential energy function.
1. Summary
Thermodynamic and structural properties of a molecular system can be precisely defined as ensemble-dependent expectations of functions of its configuration. The calculation of such expectations is feasible only with the use of Markov chain Monte Carlo (MCMC) methods or approximations thereof. Considered here are sampling propagators that do not compromise the Markov property. Included are unbiased samplers that conditionally accept proposed moves and biased samplers that unconditionally accept such moves, in particular, discretized stochastic dynamics. Many such sampling propagators are proposed in the literature, and, in virtually all cases, experiments are conducted to substantiate claims of superiority. Too often though, a good metric is not used to measure the computational cost of a propagator. The aim of this article is threefold: first, to explore some practicalities related to measuring the efficiency of a propagator; second, to highlight the superior efficiency of irreversible propagators, namely, those that do not satisfy detailed balance; and third, to provide some insight into the optimal mix of diffusive and ballistic movement for Langevin dynamics.
Let , denote the probability density function corresponding to the ensemble of interest. This function is assumed to be known only up to a multiplicative factor. An observable is an expectation for some “preobservable” . This can be estimated by the mean , where the random values are obtained from a Markov chain that samples from . Note the use here of upper case to denote random variables.
In practice, sampling performance is improved if the configuration variables are augmented with auxiliary variables , e.g., momenta, yielding phase space variables . The probablity density is extended to so that
and an MCMC scheme is constructed to produce a chain , where .
The samples from the chain tend to be highly correlated, and this greatly reduces the convergence rate as . As explained in Section 2, the variance of an estimate for is
where is the integrated autocorrelation time (IAcT) for . The effective sample size is therefore , and the appropriate metric for evaluating a propagator is the effective sample size divided by the computing time.
In a great many practical simulations, the effective sample size is probably close to zero. One can disagree on the significance of such simulations [1]. In any case, for the comparison of sampling algorithms, it is possible to choose molecular systems, restrained if necessary, for which it is feasible to attain a decent effective sample size.
Often, the spectral gap is cited as the relevant quantity. To understand its role, it is helpful to express ideas in a direct way as in Refs. [2,3]. As detailed in Section 2, introduce a forward transfer operator to express the ratio in terms of , where is the probablity density for . Let where denote the function with constant value . Assume that the operator has its spectrum strictly inside the unit circle, as it does in practice. The error in can be shown [1] to be “proportional to” and therefore to the reciprocal of the spectral gap , where is a nonunit eigenvalue of nearest 1.
Estimates of the IAcT are obtained by summing the terms of the autocorrelation function, which is constructed from autocovariances of increasing time lags normalized by the (lag zero) covariance. Each term contributes a roughly equal statistical error but a signal that decays as the lag time increases. Therefore, in practice, the terms are weighted by a function called a lag window. The lag window must be tailored to the autocorrelation function, and choosing a suitable lag window is very difficult, as mentioned in Section 2.1.
Reliable estimates of the IAcT are impractical in general. Section 3 reviews the concept of quasi-reliability, which aims to enforce a necessary condition for reliable estimates. Informally, the goal is to ensure good coverage of those “parts” of phase space that has been explored, to reduce the possibility of missing an opening to an unexplored part of phase space. More precisely, for an arbitrary subset of phase space, we ask that the proportion of samples in that subset differ from its expectation by no more than some tolerance , with, say, 95% confidence. This is shown to be true if the IAcT for any preobservable satisfies . The maximum IAcT is the greatest eigenvalue of
where denotes the adjoint with respect to the inner product
For a reversible propagator, where , is 1 less than twice the reciprocal of the spectral gap. However, for an irreversible propagator, it can be much smaller, as demonstrated by a simple example in Section 4.1, or larger as in Section 5. As a practical algorithm, it is suggested to estimate the maximum IAcT by discretizing the space of preobservables. Consideration of a quadratic energy potential suggests using a linear combination of phase space variables (and possibly quadratic terms in these variables).
The idea of seeking the preobservable that maximizes the IAcT is suggested already in Ref. [4], which considers a set of indicator functions as preobservables and uses the greatest IAcT of these to assess sampling thoroughness. In general, maximizing over a linear combination of preobservables can lead to a much larger result than taking the maximum of them individually, due to correlations that might exist between different preobservables. This does not necessarily apply, however, to those considered in Refs. [1,4].
Section 3.1 notes that that typical irreversible propagators, termed “quasi-reversible” here, have a forward transfer operator , where each of and is reversible and . For such propagators, the estimation of simplifies somewhat.
Theoretical results [5] indicate that adding irreversibility reduces the autocorrelation times of observables. Section 4 gives a couple of very elementary examples illustrating the dramatic increase in if an irreversible propagator is replaced by its reversible “counterpart” .
Discretized Langevin dynamics is a particularly effective general-purpose propagator. Unfortunately, one must specify a value for the damping coefficient . Section 5 analyzes for a quadratic potential and obtains an optimal value for the coefficient, namely, the value times the critical damping coefficient for lowest frequency . This value is such that the lowest frequency mode is moderately underdamped, with higher frequencies increasingly underdamped.
2. Preliminaries
Assuming that has probability density , the variance of the estimate is exactly
where the autocovariances
The limit gives Equation (1) where the integrated autocorrelation time
As an example of augmenting configuration space, consider , where . A good propagator for this is the BAOAB integrator [6] for Langevin dynamics, whose equations are
where M is a matrix chosen to compress the range of vibrational frequencies, , , and is a vector of independent standard Wiener processes. Each step of the integrator consists of the following substeps:
- B: ,
- A: ,
- O: ,
- A: ,
- B: ,
where is a vector of independent standard Gaussian random variables. The samples generated from this process are shown [7] to be those from a distribution that differs from the correct one by only . The special choice is the Euler–Leimkuhler–Matthews integrator [6] for Brownian dynamics with step size . Remarkably, the invariant density of this integrator differs from the correct one by only . This integrator can be expressed as a Markov chain in configuration space, with propagator
- ,
- ,
which is a discretization of Brownian dynamics
The desired samples are available as part of the process (and, as a theoretical observation, they can be recovered from the Markov chain alone, by eliminating in the two equations above and solving for ).
For any MCMC propagator, the forward transfer operator is defined so that
where and is the probability density for . In particular,
where is the transition probablity for the chain. The operator has an eigenfunction for eigenvalue .
A reversible propagator is one that satisfies detailed balance, which means that
Detailed balance is equivalent to , where the adjoint is defined by the condition that for arbitrary and . The BAOAB integrator is not reversible as a sampling propagator, except for the special case ; however, a scheme consisting of a fixed number of BAOAB steps followed by a momenta flip is reversible. The unmodified BAOAB integrator is, however, in a class of “quasi-reversible” integrators introduced in Section 3.1.
As a model problem for Brownian dynamics, given by Equation (5), consider . (The absence of boldface indicates scalar quantities.) Changing variables and dropping the prime gives the simple stochastic differential equation
where denotes a standard Wiener process. A perfect realization of at discrete points is obtained by the reversible propagator
The probablity density for satisfies the Fokker–Planck equation . Writing gives . The operator on the right-hand side has eigenfunctions with eigenvalues for . The modified version of the Hermite polynomial of degree k is given by . The forward transfer operator for the propagator defined by Equation (7) has these same eigenfunctions and has eigenvalues for . The spectral gap is . In the multidimensional case with normal mode frequencies , the time step is some fraction, say , of and the spectral gap is very nearly . To see the applicability to practical numerical integrators, consider the Euler–Leimkuhler–Matthews discretization of Equation (6):
Comparing Equations (8) and (7) and equating the coefficients of the two terms on their right-hand sides enables Equation (8) to be written in the form of Equation (7) with modified values for and . In particular, the modified value of is , so spectral gap is exactly . In the multidimensional case, where , the spectral gap for the discrete stochastics is very nearly that of the continuous stochastics.
2.1. Estimating Integrated Autocorrelation Time
Suggested [8] as a covariance estimate is the quantity
with justification in Ref. [9] (pp. 323–324).
The use of all possible terms in Equation (3) to estimate the IAcT does not converge in the limit , so, in practice, a lag window is used to increasingly damp terms as the noise to signal ratio increases:
An interesting algorithm called acor for estimating the IAcT is available on the web [10]. Estimating the IAcT can be quite difficult, and acor can give unsatisfactory results. An attempt to improve it [1] is at best marginally successful. For reversible methods, there are properties of the autocorrelation function that may be useful for improving estimates of it [8].
3. Quasi-Reliable Estimates of Sampling Thoroughness
The idea of quasi-reliability is to require that the sample size N be large enough that, with say 95% confidence, the estimated probability of any subset of phase space differs by no more than from its correct value. More specifically, for any subset of phase space, an estimate of must satisfy
Because
where is the IAcT for , it is enough that
For molecular simulations, this requires that only those conformations or clusters of conformations having a probability greater than be sampled.
In practice, molecular systems have many symmetries, which dramatically reduces the amount of sampling needed. For example, water molecules are generally considered interchangeable as are many subsets of atoms on a given molecule, e.g., the 2 hydrogen atoms of any water molecule. More formally, there are permutations P of the variables such that and that where . For such symmetries P, the quasi-reliablity requirement considers only those for which .
It is helpful to express the IAcT in terms of the forward transfer operator. It can be shown that
and, in particular,
using the fact that . The integrated autocorrelation time can be rewritten as
where
which is a self-adjoint operator.
For a reversible propagator, for which and hence is self adjoint, an arbitrary preobservable u is in many cases expressible as a linear combination of the eigenfunctions of , corresponding to eigenvalues . (For a more rigorous treatment, see Ref. [8] (Section 2).) The IAcT for u is then simply a weighted average, of the values
with weights . This is maximized for , since is the largest of these values. Note that, for negative, could be much less than 1. Having may appear paradoxical until it is recognized that Equation (1) is simply an asymptotic approximation for .
For the simple example with , the eigenfunction . The indicator function that is richest in is the one with , for which the first weight is . This means that the IAcT for is at least of the maximum IAcT. For a multimodal distribution, the eigenfunction corresponding to the subdominant eigenvalue [2,3] is closer than is the function to an indicator function modulo a constant. Therefore, little is lost and simplicity is gained, if we use the maximun IAcT over all observables satisfying the symmetries instead of just indicator functions:
where
is our set of preobservables. This can be simplified to
To see this, note that the same supremum is obtained for both objective functions if the function u is restricted so that and that for such a function u the two objective functions are equal.
For the simple example of Equation (8), the IAcT is maximized by . In the case of a multidimensional Gaussian distribution, the maximum occurs for linear combination of where is the eigenvector of the Hessian of corresponding to its smallest eigenvalue . For multimodal distributions in one dimension, it appears that the maximizing preobservable is qualitatively similar to q in the sense that it is monotonic [2,3].
As is customary when seeking an unknown function, one considers a finite linear combination of basis functions where the are chosen to maximimize the IAcT. The number of basis functions is limited by computational cost. The result of Section 5 hints that the ideal number might be . From Equation (10), the autocovariance for such is
where
Consequently,
which is a solution of the generalized eigenvalue problem
The approximation of Equation (14) improves with the number of basis functions.
Without information about the actual distribution , a general choice for basis functions might be linear polynomials, which are the “subdominant” eigenfunctions for a Gaussian distribution. Simple examples in Ref. [1] (consisting of a mixture of two Gaussians, a one-node neural “network”, and logistic regression) demonstrate that the use of linear basis functions can yield an IAcT much greater than that of a preobservable of “interest”. For molecular simulation, it is clear that instead of atomic coordinates, a better choice of a basis function is the distance between two atoms, each of which is uniquely distinguishable. In particular, for a protein, one might choose -carbons distributed along the backbone chain of a protein. For further suggestions, consult Ref. [11], which considers the automatic construction of indicator functions for estimating , based on the dynamics of the propagator.
3.1. Quasi-Reversible Propagators
As stated above, the BAOAB integrator would be reversible if the final B substep were modified to include a momenta flip, i.e.,
- BR: .
However, reversing direction runs counter to intuition. Additionally, empirical evidence [12] favors irreversible propagators. If the flipped BAOAB integrator is followed by another momenta flip, the result is the original irreversible BAOAB integrator. More generally, a sampler might be said to be “quasi-reversible” if its forward transfer operator where each of and is reversible and . For a momenta flip, the operator is defined by .
Quasi-reversible propagators are special in that their covariance matrices satisfy a special property if basis functions are chosen so that
and and are identity matrices of possibly different dimension. Such basis functions are easy to construct since any function u can be written as a sum of its “even part” and its “odd part” . In particular, using the fact that ,
The matrix thus partitions into four blocks. The symmetric part of consists of the two diagonal blocks, and the skew-symmetric part consists of the two off-diagonal blocks. Empirical estimates of lack these symmetry properties. The expected symmetries provides twice as many samples for estimating the sampling error in the off-diagonal elements. Additionally, since the IAcT requires only the symmetric part of , it is unnecessary to compute the off-diagonal blocks, and the eigenvalue problem decouples into two smaller problems. In addition, it follows that the maximizing linear combination is either a linear combination of the even functions or of the odd functions. For molecular dynamics at least, velocities “relax” much more quickly than positions, so it seems that the long time scales are present only in the position coordinates, so only the block might be computed.
4. Irreversible Samplers and Their Superiority
Uniform sampling—if it could be used—converges like , which is superior to the convergence of random sampling. It would be desirable to combine them by promoting near-uniform sampling within layers of near-constant energy and using diffusion to move among energy layers.
4.1. A Very Simple Example
The following very simple example is a discrete analog of Example 2.8 of Ref. [5] and similar to an example of Ref. [13]. Assuming probabilities are represented as row vectors, let be an n by n probability transition matrix given by
where . The stationary probability vector is . The inner product for two row vectors , is , and the adjoint of a transition matrix is its transpose. Since is a circulant matrix, both it and its adjoint have as eigenvectors , where denotes the nth root of unity . A straightforward, though lengthy, calculation shows that
for , and
Therefore,
but
This a most elementary illustration of the assertion [5] that “the asymptotic variance for every observable can be made as small as desired under large irreversible drift”. If , the IAcT is likewise much less than 1 despite the very strong correlation between successive values of the state j. The reason for this is that the IAcT is a measure of sample quality not independence. The measure simply says that N samples are as good as independent random samples. The operator encourages a uniform sampling, which is better than uncorrelated random samples. However, as shown in the example that follows, such a dramatic difference between (one less than twice) the reciprocal of the spectral gap and the IAcT does not hold when sampling is inhibited more by energy than by entropy barriers. A reversible propagator can be formed from this simple example by using instead the symmetric part of its propagator: . This time
and
Therefore
and
Clearly, the irreversible propagator is much better for .
4.2. A Very Simple Example with a Barrier
Consider the by transition matrix given by
If were zero, the eigenvalue 1 would have multiplicity 2, with orthogonal eigenvectors given by the vector of all ones and by . For small , it is expected that the eigenvector corresponding to the subdominant eigenvalue would be a perturbation of . Indeed, it happens that . This also holds for , so the IAcT for is . This suggests a value of about for the IAcT of . This is corroborated by numerical computation, as shown in Table 1a.
The excess IAcT due to making the propagator reversible is given by Table 1b.It appears to grow quadratically with n, consistent with the diffusive nature of the propagator. Summing pairs of entries from the two tables shows that for this example the advantage of irreversibility depends on the relative importance of entropy barriers to energy barriers, which is consistent with intuition from molecular dynamics.
5. Optimal Langevin Damping for a Model Problem
To analyze the effect of the damping parameter on the IAcT for Langevin dynamics, given by Equation (4), consider the standard model problem . Changing variables , , and dropping the primes gives
Assume exact integration with step size .
The analysis is rather lengthy, so for the benefit of the reader who wishes to omit it, the discussion and conclusions are given here:
- Reaching precise conclusions is difficult for most of the analysis unless is bounded above by some constant of order 1, which seems to be satisfied in practice. This assumption underlies the statements that follow.
- The spectral gap is an increasing function of , so for a multidimensional quadratic potential energy, the value of that maximizes the spectral gap depends on the lowest frequency .
- The spectral gap is maximized for , corresponding to an underdamped system, for which the spectral gap is .
- The eigenfunctions of the operator can be partitioned into eigenspaces , , where is a linear combination of specific polynomials of degree k in and p. The greatest eigenvalue of is where is the maximum IAcT over .
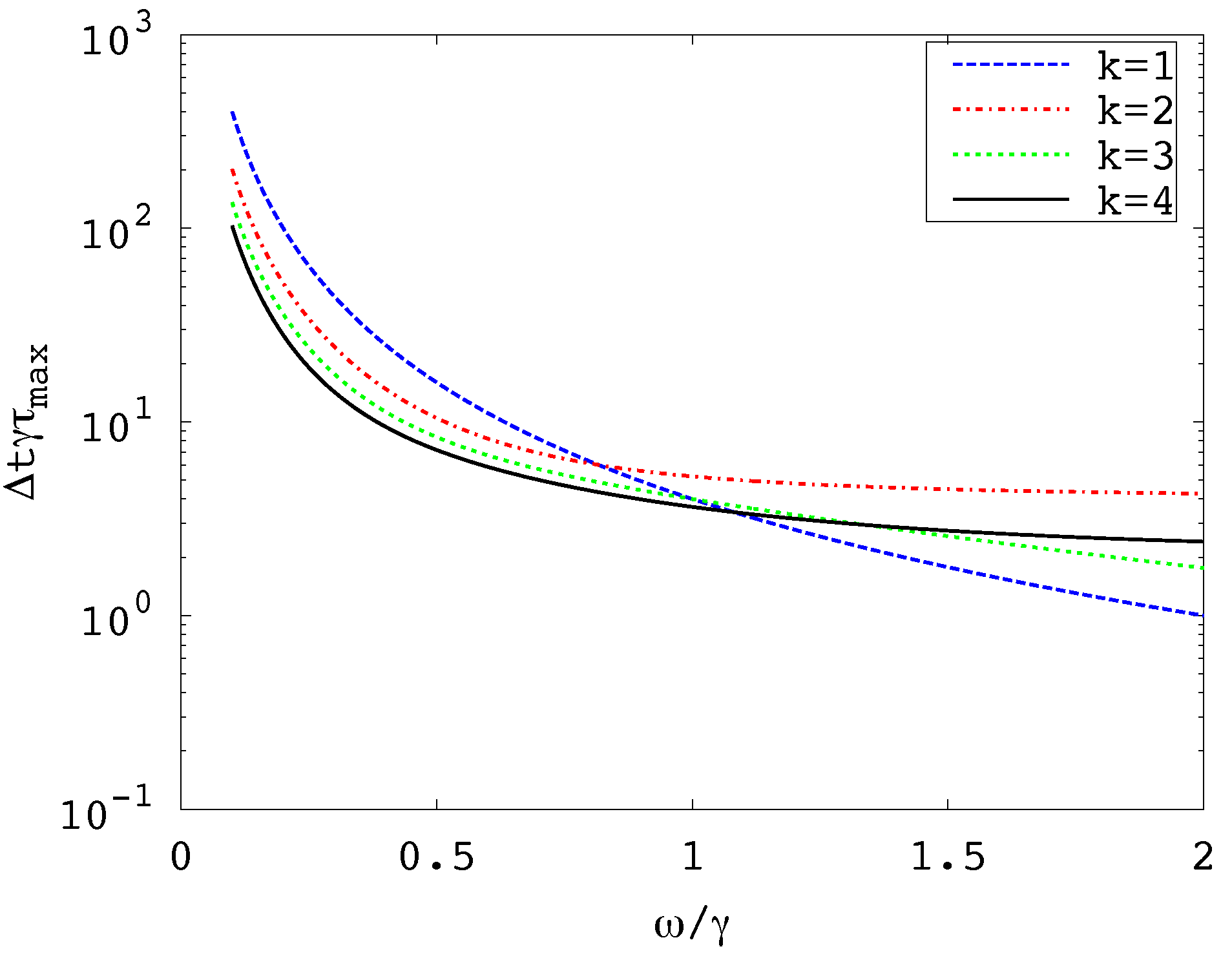
- Figure 1 shows that, for fixed and , the value is an increasing function of , at least for . Hence, as for the spectral gap, it is the lowest frequency that dictates the maximum .
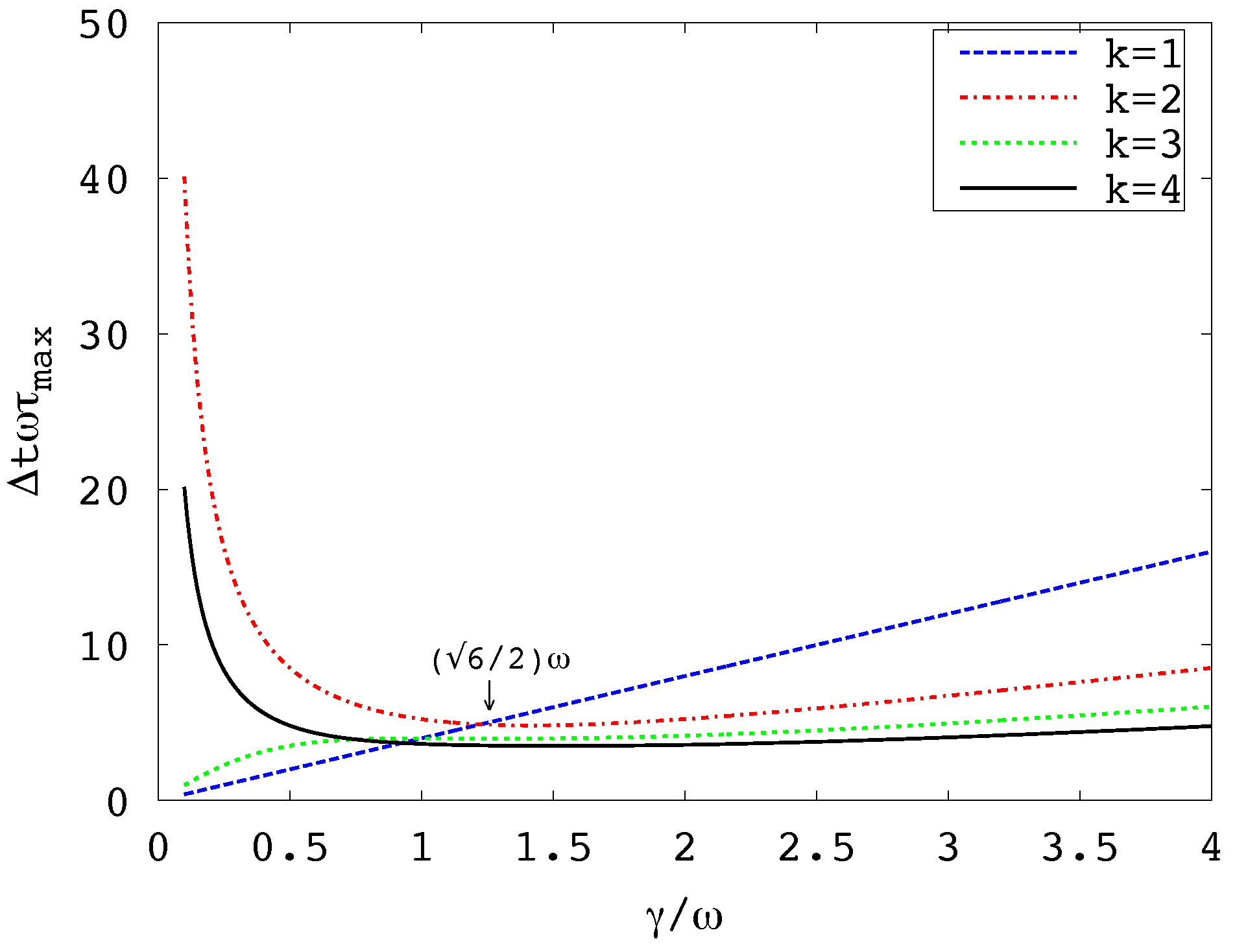
- Figure 2 indicates that, for fixed and , the maximizing is either or , depending on the value of . The optimal damping coefficient is , for which .
- For the preobservable , and, indeed, for any odd polynomial, the IAcT becomes arbitrary small as goes to zero. This does not mean, however that the variance goes to 0, because Equation (1) is an asymptotic result, and the IAcT is a prefactor for the leading order term in the expression for the variance. The next order term would dominate if were very small. An order error is characteristic of uniform sampling, which would be the consequence of nearly ballistic movement. In addition, odd polynomials are special in that their expectation is independent of total energy, so it matters not that barely diffusive movement samples different values of total energy only at a very slow rate.
- The eigenfunction for is a specific linear combination of and . For quadratic polynomials, the total energy does affect its expected value, which is why it is necessary that be large enough to sample different energies on a reasonable time scale.
5.1. The Forward Transfer Operator
The forward transfer operator is
where
and is the Fokker–Planck operator [14] (Equations (10.1)–(10.3), (10.9))
Therefore,
where
Using the relation , it is easy to show that the adjoint
5.2. Gamma for Maximum Spectral Gap
Ref. [14] (Chapter 10, Equations (1), (2), (3b), (9), (22), (52), (60), (71), (72), (74), (77), (78), (82) and (83)) gives the eigenvalues of as
with eigenfunctions
where
with the radical sign denoting the principal square root, and operators , defined by
The operator has eigenfunctions and the same eigenvalues; has these same eigenfunctions and has eigenvalues . See Ref. [15] for a more general result.
For , one has , and
In the case , has a double eigenvalue but one eigenfunction and one generalized eigenfunction , satisfying . This results in behavior involving a linear combination of and .
The eigenvalue nearest 1 depends on . For small enough , it is , and the spectral gap is for and otherwise. To maximize the spectral gap, choose to be no greater than , corresponding to an underdamped system.
5.3. Gamma for Maximum IAcT
To obtain , one needs eigenelements for , given by Equation (2) with . Note that the subspace of polynomials of degree is closed under application of and . Moreover, this holds separately for subspace of odd polynomials of degree for k odd and for subspace of even polynomials of degree for k even. It also applies to operators , , , and . Hence, the are eigenspaces for . These eigenspaces can be further decomposed as follows. Let for , and let for . The claim is that is an eigenspace, of dimension . To confirm this, it is enough to show that for any , , which follows almost immediately, since and . Let be a basis for chosen so there are even functions of p followed by odd functions of p. In particular,
for , respectively. The polynomials in and in p are modified versions of Hermite polynomials. We have for some matrix of constants A, given by
(cf. Ref. [14], Equations (10.96) and (10.97) for .) We have and . Therefore, from Equations (13) and (14), one has
and
For each value of k, is the maximum eigenvalue of
As explained in Section 3.1, if the basis functions are re-ordered so that those that are even functions of p precede those that are odd functions of p, the eigenvalue problem splits into two nearly equal parts.
For , where and
The covariance matrix , and matrix (17) is where
Using the identity , one gets that the eigenvalues of matrix (17) are
The greater of is , and it is a straightforward exercise to show that is an decreasing function of as long as
In practice, a numerical integrator is used, whose step size is chosen so that where is some fractional value, e.g., , and L is the magnitude of largest eigenvalue of the Jacobian matrix of the right-hand side of the system of (first-order) stochastic differential equations. In particular,
otherwise, it holds that . Hence, Inequality (18) is more than satisfied. It is more complicated to analyze the behavior of values of for , so we exploit the smallness of and to do an asymptotic analysis. From Expression (17), one sees that for , its equals where is the greatest eigenvalue of
For , one has and , corresponding to the eigenfunction . For , one has
, and the largest eigenvalue for Expression (20) is
corresponding to an eigenfunction that is some linear combination of and . Again is a decreasing function of for small enough . For general k, the size of the elements of A in Equation (16) increase with , which suggests that for practical values of , the largest eigenvalue for Expression (20) decreases with . This can be confirmed numerically. To reduce the number of parameters, write , and rewrite Expression (20) as
The value is the largest eigenvalue of Matrix (21), so is a function only of the ratio . Figure 1 plots this quantity for , confirming that is decreasing function of for fixed values of and .
Therefore, for a multidimensional quadratic potential, is very likely to be determined by the lowest frequency mode. (This is readily established for the spectral gap for reasonable values of .)
Having established that the lowest frequency mode is most likely responsible for , let denote the lowest frequency , and consider the optimal choice of . From Matrix (21), observe that is a function only of . Accordingly, we choose to minimize . However, may depend on , but only if , according to Equation (19). Let us initially ignore this possibility and revisit it after determining the optimal .
Assuming that the maximum of is attained for or , there are two possible locations for the best . One is the choice , for which and . The other is the choice where for both and . The latter is the better choice. This and the assumption that the maximum occurs for is supported by Figure 2, which plots as a function of for fixed values of and . Since , we see from Equation (19) that there is no concern about limiting the value of .
Note that for the optimal , the dynamics is underdamped in every mode.
6. Discussion and Conclusions
It is asserted in the literature [1,4] that, for comparing MCMC propagators and for ensuring reasonably reliable simulation results, it is of great value to estimate the maximum autocorrelation time over all possible observables. Certainly, this would seem desirable for comparing propagators, since it is best to assume as little as possible about the actual observables that are to be estimated from the Markov chain. In addition, the longest IAcT would be more reliably estimated than any other IAcT, because its accurate estimation would call for a greatest number of samples; moreover, the accuracy of estimates of other IAcTs might be influenced by the longest IAcT. Unfortunately, estimating IAcTs and assessing such estimates is a difficult task, which can benefit greatly from further research.
In this article, it is suggested that the maximum IAcT be estimated by considering an arbitrary linear combination of basis functions chosen to capture the lowest frequency motions of the dynamics of the MCMC chain. It is also worth considering the approach based on a set of well chosen indicator functions [11].
Another quantity for measuring performance of an MCMC propagator is the spectral gap. It is related to equilibration time, but as a predictor of IAcTs, it can be arbitrarily too pessimistic or it can be too optimistic. Such is the case for irreversible propagators, especially for energy landscapes where entropy barriers dominate energy barriers.
Shorter integrated autocorrelation times are thus a primary consideration in the design of MCMC propagators. Simple examples are constructed to explain how irreversibility might help, though their relevance to practical propagators is unclear. Nonetheless, it is advantageous not to insist on reversibility. In particular, the ballistic component of propagators like hybrid Monte Carlo and Langevin dynamics may offer dramatic speedups for overcoming entropy barrriers, though no advantage for energy barriers.
Irreversible propagators typically have a parameter that determines the extent of diffusive behavior. For discrete Langevin dynamics applied to a multidimensional quadratic potential, the optimal value corresponds to slightly underdamped dynamics for the lowest frequency mode, with other modes experiencing even lighter dampling. However, this conclusion is not necessarily indicative of the optimal damping for the usual situation, in which there a multiplicity of energy minima, and further studies are needed.
In a nutshell, general-purpose sampling benefits greatly from the use of irreversible propagators in extended state space, with “diffusion parameter(s)” chosen to minimize the maximum integrated autocorrelation time, which for a quadratic potential energy corresponds to moderately underdamped dynamics in the lowest frequency mode.
Author Contributions
Youhan Fang performed the analysis for Section 5.2 and the computation for Section 5.3. Robert D. Skeel did the analysis for Section 3.1, Section 4, Section 5.1 and Section 5.3 and wrote the paper. Both authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Fang, Y.; Cao, Y.; Skeel, R. Quasi-Reliable Estimates of Effective Sample Size. arXiv, 2017; arXiv:1705.03831v2. [Google Scholar]
- Schütte, C.; Huisinga, W. Biomolecular Conformations as Metastable Sets of Markov Chains. In Proceedings of the 38th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 4–6 October 2000; pp. 1106–1115. [Google Scholar]
- Schütte, C.; Sarich, M. Metastability and Markov State Models in Molecular Dynamics; American Mathematical Society: Providence, RI, USA, 2013. [Google Scholar]
- Lyman, E.; Zuckerman, D.M. On the Structural Convergence of Biomolecular Simulations by Determination of the Effective Sample Size. J. Phys. Chem. B 2007, 111, 12876–12882. [Google Scholar] [CrossRef] [PubMed]
- Rey-Bellet, L.; Spiliopoulos, K. Irreversible Langevin Samplers and Variance Reduction: A Large Deviations Approach. Nonlinearity 2015, 28, 2081–2104. [Google Scholar] [CrossRef]
- Leimkuhler, B.; Matthews, C. Rational Construction of Stochastic Numerical Methods for Molecular Sampling. Appl. Math. Res. Express 2013, 2013, 34–56. [Google Scholar] [CrossRef]
- Leimkuhler, B.; Matthews, C.; Stoltz, G. The Computation of Averages from Equilibrium and Nonequilibrium Langevin Molecular Dynamics. IMA J. Numer. Anal. 2016, 36, 13–79. [Google Scholar] [CrossRef]
- Geyer, C.J. Practical Markov Chain Monte Carlo. Stat. Sci. 1992, 7, 473–511. [Google Scholar] [CrossRef]
- Priestly, M.B. Spectral Analysis and Time Series; Academic Press: Cambridge, MA, USA, 1981. [Google Scholar]
- Goodman, J. Acor, Statistical Analysis of a Time Series. 2009. Available online: http://www.math.nyu.edu/faculty/goodman/software/acor/ (accessed on 4 August 2014).
- Zhang, X.; Bhatt, D.; Zuckerman, D.M. Automated Sampling Assessment for Molecular Simulations Using the Effective Sample Size. J. Chem. Theory Comput. 2010, 6, 3048–3057. [Google Scholar] [CrossRef] [PubMed]
- Cancés, E.; Legoll, F.; Stoltz, G. Special Issue on Molecular Modelling: Theoretical and Numerical Comparison of Some Sampling Methods for Molecular Dynamics. ESAIM Math. Model. Numer. Anal. 2007, 41, 351–389. [Google Scholar] [CrossRef]
- Diaconis, P.; Holmes, S.; Neal, R.M. Analysis of a Nonreversible Markov Chain Sampler. Ann. Appl. Probab. 2000, 10, 726–752. [Google Scholar] [CrossRef]
- Risken, H. The Fokker-Planck Equation. Methods of Solution and Applications; Springer Series in Synergetics; Springer: New York, NY, USA, 1984; Volume 18. [Google Scholar]
- Kozlov, S. Effective diffusion for the Fokker-Planck equation. Math. Notes 1989, 45, 360–368. [Google Scholar] [CrossRef]
Figure 1.
vs. for .

Figure 2.
vs. for .


{kind=link}
{kind=link}
Table 1.
is the IAcT for and is that for .
| (a) | |||
| 0.1 | 0.01 | 0.001 | |
| 10 | 90 | 990 | 9990 |
| 100 | 900 | 9900 | 99,900 |
| 1000 | 9000 | 99,000 | 999,000 |
| (b) | |||
| 0.1 | 0.01 | 0.001 | |
| 10 | 35 | 33 | 33 |
| 100 | 3910 | 3511 | 3355 |
| 1000 | 403,612 | 389,921 | 351,047 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Skeel, R.D.; Fang, Y. Comparing Markov Chain Samplers for Molecular Simulation. Entropy 2017, 19, 561. https://doi.org/10.3390/e19100561
AMA Style
Skeel RD, Fang Y. Comparing Markov Chain Samplers for Molecular Simulation. Entropy. 2017; 19(10):561. https://doi.org/10.3390/e19100561
Chicago/Turabian StyleSkeel, Robert D., and Youhan Fang. 2017. "Comparing Markov Chain Samplers for Molecular Simulation" Entropy 19, no. 10: 561. https://doi.org/10.3390/e19100561
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.